2 Data Report - Linguistic and Structural Annotation
In the CWB version of the corpus, the data is both linguistically and structurally annotated. Using the language of the CWB, most linguistic annotation layers are provided in the form of positional attributes on token level. Aside from a tokens’s surface form (the word itself), these might include Part-of-Speech tags or lemmata and can be used to formulate complex queries. In contrast, structural attributes describe regions of the corpus characterized by a set of metadata such as a date, a specific speaker or a combination of different attributes. Structural attributes resemble variables one can use to conduct a targeted analysis of the textual data.2
In the following, linguistic annotation layers are presented first. Afterwards, the major structural attributes are presented. To illustrate the possibilities this data structure provides for analysis, some parsimonious examples of code are provided along with the presentation of different attributes. These show the syntax used by the polmineR R package (version 0.8.9.9001).
2.1 Linguistic Annotation
GermaParl is linguistically annotated. Aside from tokenization, the data was lemmatized and Part-of-Speech-Tags (POS-Tags) as well as Named Entities were added. Lemmata and POS-Tags have been added on token-level. An overview of linguistic annotation layers annotated as positional attributes can be found in table 2.1.
| p-attribute | description | values |
|---|---|---|
| word | the word as it occurs in text | word |
| upos | the part-of-speech-tag of the word according to the Universal Dependencies Tagset | for example NOUN or CONJ |
| xpos | the part-of-speech-tag of the word according to the Stuttgart-Tübingen Tagset¹ | for example ADJA, NN, VVINF |
| lemma | the lemmatized form of the word | lemma |
| 1 see for example the overview provided here: https://www.ims.uni-stuttgart.de/forschung/ressourcen/lexika/germantagsets/ (2023-12-22) |
As illustrated by table 2.2, the corpus can be represented as a so-called token stream. The text can be read vertically with each column being a specific annotation layer.
| cpos | word | xpos | upos | lemma |
|---|---|---|---|---|
| 0 | Meine | PPOSAT | PRON | mein |
| 1 | Damen | NN | NOUN | Dame |
| 2 | und | KON | CCONJ | und |
| 3 | Herren | NN | NOUN | Herr |
| 4 | ! | $. | PUNCT | ! |
| 5 | Abgeordnete | NN | NOUN | Abgeordnete |
| 6 | des | ART | DET | die |
| 7 | Deutschen | ADJA | PROPN | deutsch |
| 8 | Bundestags | NN | PROPN | Bundestag |
| 9 | ! | $. | PUNCT | ! |
| Note: | ||||
| The first ten tokens of the corpus comprise the speech of Paul Löbe, 1949-09-07 |
These linguistic features can be used to formulate complex queries. For example, one could be interested in text sequences in which the term “Liebe” (as love) occurs as a noun (“NN”) and is thereby different to the same German word which can be used as a form of address (“Liebe” as in the English “Dear”). In polmineR the appropriate syntax would look like the following line of code.
For an in-depth introduction into the CQP query language used here, please consult either the aforementioned UCSSR teaching materials or the CQP manual by Stephanie Evert and the CWB Development Team.
While also part of the linguistic annotation, Named Entities are not added as positional attributes. They can span multiple tokens and are encoded as structural attributes which are discussed later. As linguistic annotation, the named entities annotation distinguishes between the four classes “LOCATION”, “ORGANIZATION”, “PERSON” and “MISC”. These are added and addressed as the structural attribute ne_type. The following code chunk chows one way to perform a CQP query using a structural attribute.
2.2 Structural Annotation
Different regions of the corpus are characterized by different metadata. This structural annotation comprises of different attributes which are either on the document level (temporal information such as date, year or legislative period as well as the session number), on the level of utterances made by different speakers (speaker name, party affiliation, parliamentary group affiliation, speaker role) or below the utterance level like the annotation of sentences or paragraphs. Importantly it is also annotated whether a region refers to a ordinary speech or is an interjection of another speaker or another non-vocal contribution. In table 2.3 the structural attributes of the GermaParl corpus are described in the way they are encoded in the CWB version of the corpus.
| s-attribute | description | values |
|---|---|---|
| protocol | protocol node corresponding to the document node in the TEI/XML | … |
| protocol_lp | legislative period | 1 to 19 |
| protocol_no | session/protocol number | 1 to 282 |
| protocol_date | date of the session | YYYY-MM-DD (e.g. ‘1999-11-25’) |
| protocol_year | year of the session | 1949 to 2021 |
| protocol_url | the url of the source document of the session | an url |
| protocol_filetype | the file type of the source document of the session | txt, xml, pdf |
| speaker | speaker node corresponding to the speaker node in the TEI/XML | … |
| speaker_who | speaker name as found in the protocol (might have been consolidated) | speaker name, e.g. “Müller (Berlin)” |
| speaker_name | consolidated and disambiguated speaker name | speaker name, e.g. “Johannes Müller” |
| speaker_parlgroup | parliamentary group of the speaker | name of a parliamentary group, e.g. “CDU/CSU” |
| speaker_party | party of the speaker | name of a party, e.g. “CDU” |
| speaker_role | role of the speaker | government, mp, presidency |
| p | regions making up paragraphs in the CWB corpus | NULL |
| p_type | type of the paragraph, whether a paragraph represents an ordinary speech or an interjection | speech or stage |
| ne | regions making up named entities in the CWB corpus | NULL |
| ne_type | type of the named entity | LOCATION, MISC, ORGANIZATION, PERSON |
| s | regions making up sentences in the CWB corpus | NULL |
In the following, further attributes of the corpus are described briefly.
Speeches
Addressing an obvious omission first, the current version of GermaParl does not provide a structural attribute for individual speeches. The definition of a speech might not be the same for each user of the resource. In particular, not every brief interruption should necessarily result in a long speech being considered as two or more separate speeches. However, using the attributes for speakers and dates, speeches can be reconstructed by creating specific subcorpora with polmineR.
speeches <- as.speeches("GERMAPARL2",
s_attribute_name = "speaker_name",
s_attribute_date = "protocol_date",
gap = 50)The text itself is not filtered, but the structural attributes p_type and ne_type provide the possibility to subset the text to filter out interjections, for example. A previous Release Note discussed the hierarchical structure of the data in some detail. The following code example illustrates this:
Size and Time
The entire corpus comprises of 270 million tokens. The corpus covers the period between 1949-09-07 and 2021-09-07. Figure 2.1 shows the temporal distribution of tokens over the corpus which can be accessed via the structural attribute protocol_year.
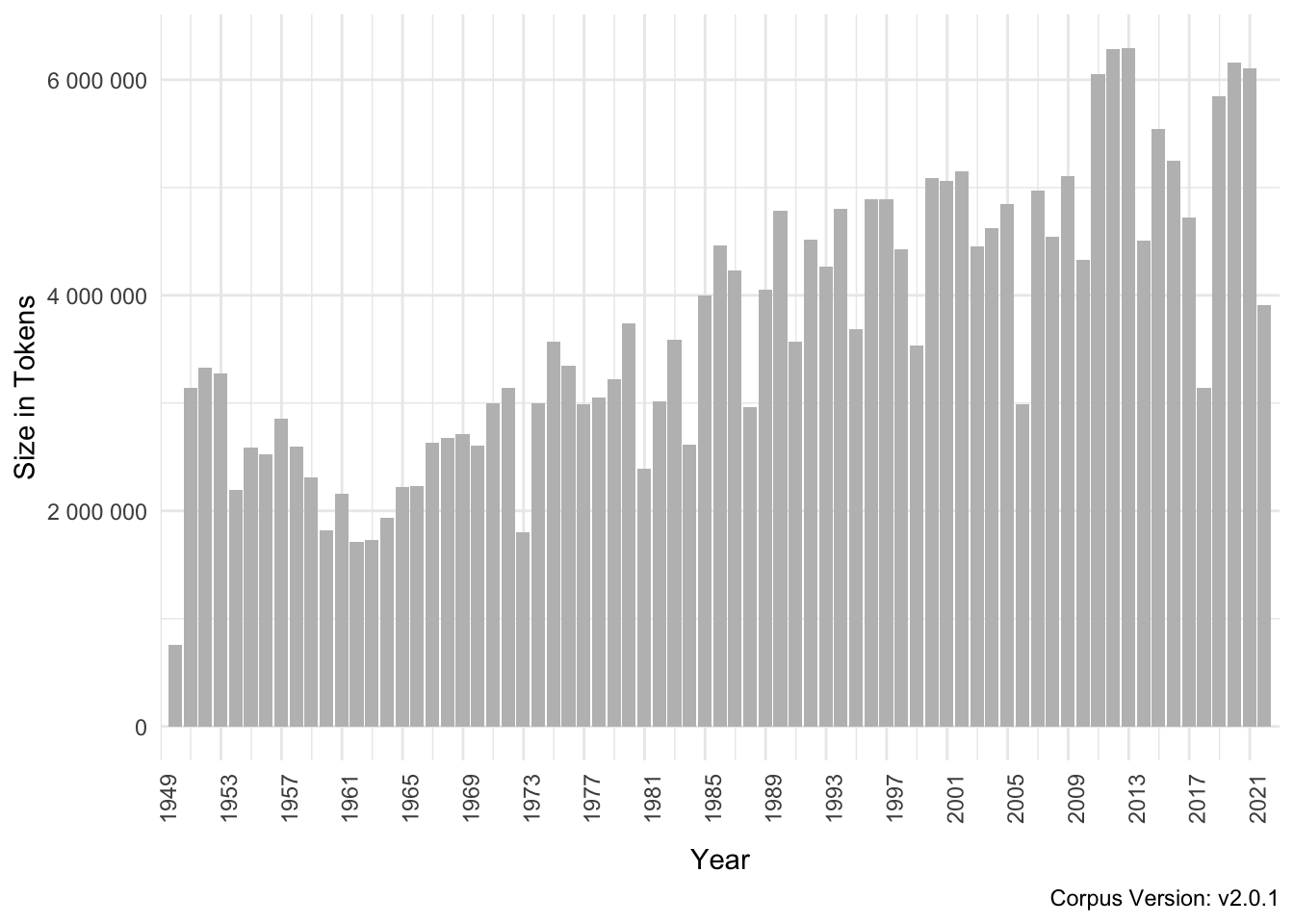
Figure 2.1: GermaParl Corpus - Tokens per Year
It becomes apparent that some years exhibit more parliamentary activity than others. Election years are clearly distinguishable in this regard. Furthermore, over the course of the years, the number of tokens per year increases. This seems to be caused mainly by an increase in the number of speeches per session. In addition, while the longest speeches were held at the beginning of the German Bundestag (in the first three legislative periods), after a drop following this initial period of high activity, the mean length of speeches also increases over the course of time.
the date of a session is stored in the format of YYYY-MM-DD. As additional temporal attributes the legislative period, the session and the year are provided.
Parliamentary Groups
The parliamentary group a speaker is affiliated to can be addressed via the structural attribute speaker_parlgroup. There are 23 parliamentary groups in the corpus which are illustrated in table 2.4.
| speaker_parlgroup | size |
|---|---|
| AfD | 2575313 |
| BP | 257936 |
| CDU/CSU | 66511854 |
| DA | 30652 |
| DIE LINKE | 9129840 |
| DP | 1369798 |
| DP/FVP | 119581 |
| DRP | 86945 |
| FDP | 29068928 |
| FU | 212937 |
| FVP | 55068 |
| GB/BHE | 595228 |
| GRUENE | 19648074 |
| KPD | 1147443 |
| NA | 73608998 |
| NR | 31854 |
| PDS | 3900412 |
| SPD | 60602427 |
| SRP | 12601 |
| WAV | 163687 |
| Z | 344380 |
| fraktionslos | 1014154 |
| parteilos | 11147 |
Figure 2.2 shows the absolute number of tokens uttered by each parliamentary group.
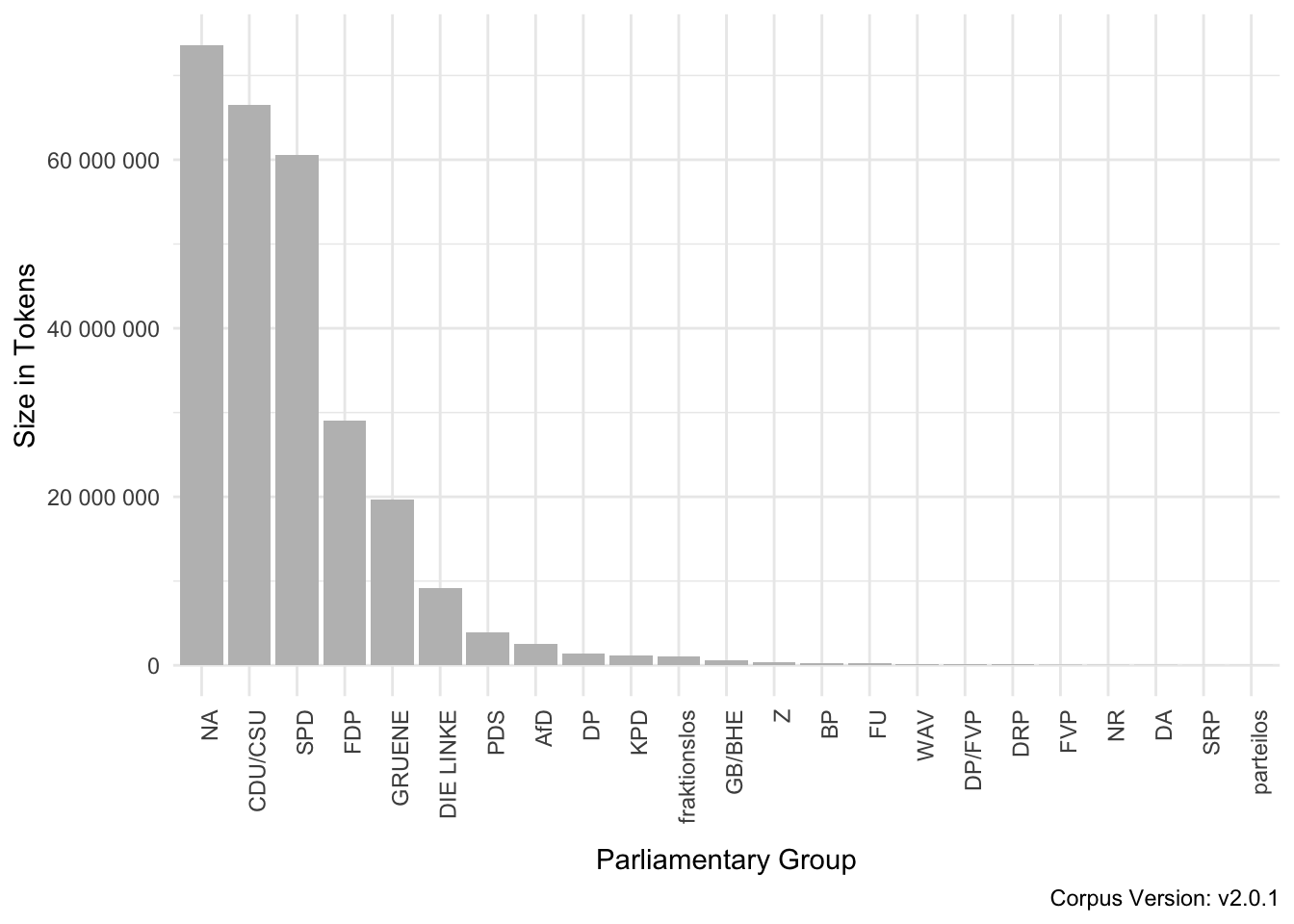
Figure 2.2: Number of Tokens per Parliamentary Group in the GermaParl corpus
Note that only members of parliament have a parliamentary group. For all other speakers, this value will be “NA”. Furthermore, different versions of the same parliamentary group’s name have been harmonized under one label.
Parties
The party affiliation can be addressed via the structural attribute speaker_party. There are 31 parties in the corpus. Table 2.5 as well as figure 2.3 illustrate the absolute number of tokens uttered by each party.
| speaker_party | size |
|---|---|
| AfD | 2519388 |
| BHE | 535 |
| BHE|CDU | 52542 |
| BP | 341223 |
| CDU | 72606115 |
| CDU oder parteilos | 169397 |
| CSU | 24896652 |
| DIE LINKE | 10334921 |
| DKP-DRP | 154280 |
| DP | 1775734 |
| DPS | 2505 |
| DP|CDU | 104070 |
| DSU | 1061 |
| Die PARTEI | 19688 |
| FDP | 41368495 |
| FDP|FVP | 120716 |
| FDV | 179 |
| FVP | 5004 |
| GB/BHE | 554977 |
| GDP | 22933 |
| GRUENE | 23133575 |
| KPD | 1147592 |
| LKR | 54271 |
| NA | 901937 |
| PDS | 4506397 |
| Partei Rechtsstaatlicher Offensive | 2679 |
| SPD | 84261670 |
| SSW | 8746 |
| WAV | 257581 |
| Z | 490279 |
| parteilos | 684115 |
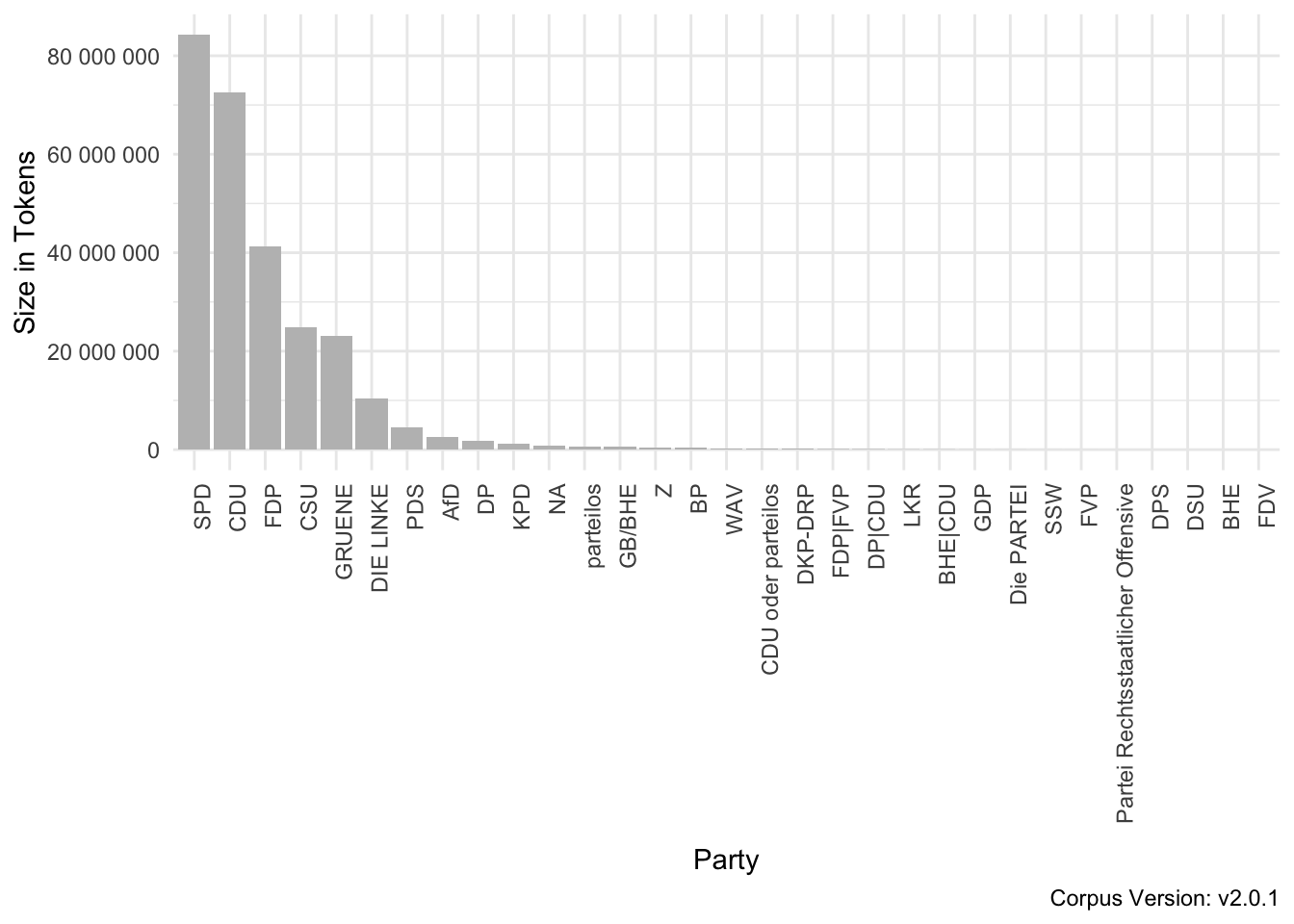
Figure 2.3: Parties in the GermaParl corpus
Note: The speaker with the label “CDU oder parteilos” is Ludwig Erhard. The timing of Erhard’s party affiliation seems to be unclear (see for example https://www.ludwig-erhard.de/stichworte/ludwig-erhard-und-die-cdu/).
Similar to parliamentary groups, there can be a number of different names for the same party over the years. These could be either harmonized in the external data or in the final data set. For now, we opted for the latter.
Roles
There are 6 different roles a speaker can occupy: governmental actors (“government”), member of parliament (“mp”), presidential speaker (“presidency”) as well as miscellaneous speakers (which can represent a number of roles such as the head of state (Bundespräsident) or (international) guest speakers) and speakers of the federal council which attend the sessions of the Bundestag occasionally. In addition, the parliamentary commissioner (Wehrbeauftragte:r des Deutschen Bundestages) is annotated. Table 2.6 and figure 2.4 provide information about the distribution of roles in the corpus. These different roles are accessed via the s-attribute speaker_role.
| speaker_role | size |
|---|---|
| federal_council | 2685510 |
| government | 43034066 |
| misc | 95275 |
| mp | 196924548 |
| parliamentary_commissioner | 130833 |
| presidency | 27629025 |
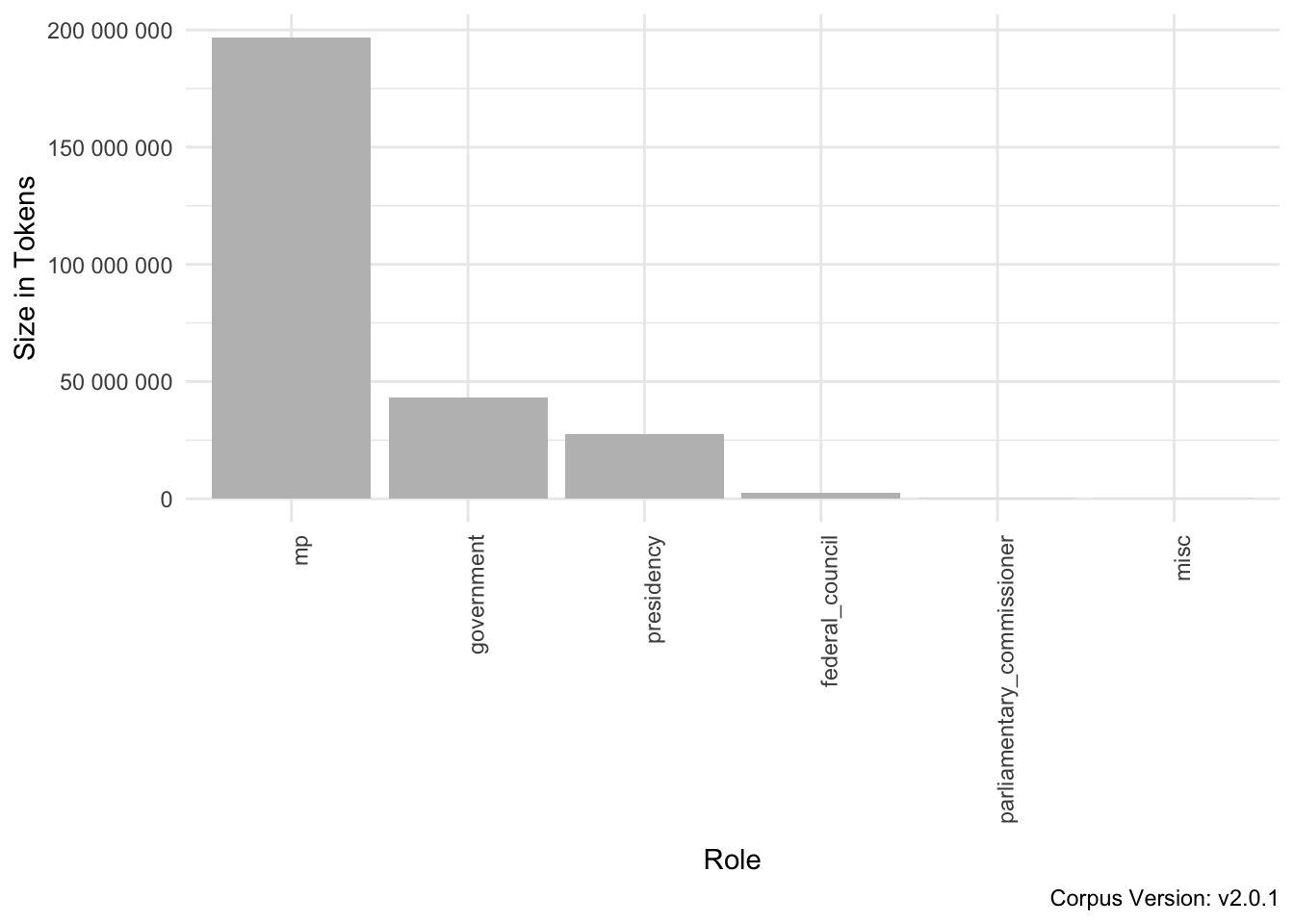
Figure 2.4: Parliamentary Roles in the GermaParl corpus
Speakers
The structural attribute speaker_name identifies individual speakers. Table 2.7 shows the 20 speakers who utter the most words in the corpus.
| speaker_name | size |
|---|---|
| Wolfgang Schäuble | 1551050 |
| Richard Jaeger | 1479986 |
| Hermann Otto Solms | 1415667 |
| Norbert Lammert | 1414751 |
| Helmut Kohl | 1402662 |
| Carlo Schmid | 1400575 |
| Petra Pau | 1379872 |
| Franz Josef Strauß | 1367877 |
| Eugen Gerstenmaier | 1332287 |
| Helmut Schmidt | 1319894 |
| Wolfgang Thierse | 1132247 |
| Annemarie Renger | 1116867 |
| Heinz Westphal | 1115324 |
| Angela Merkel | 1040660 |
| Gerhard Schröder | 1023329 |
| Hermann Schmitt-Vockenhausen | 1021189 |
| Antje Vollmer | 1015376 |
| Dieter-Julius Cronenberg | 1012807 |
| Otto Graf Lambsdorff | 993918 |
| Richard Stücklen | 949280 |
Paragraphs and Sentences
The boundaries of individual paragraphs and sentences are annotated. It is important to note that in table 2.3 the value for the structural attributes p and s is NULL. This means that regions for paragraphs and sentences are annotated and available within the corpus but they do not have any values which can be directly accessed.
Introductory examples of potential ways to use sentence annotation is shown in one session of the “Cookin’ with GermaParl” Webinar Series.
As shown above, paragraphs have an attribute “type” which is used to differentiate between paragraphs which contain ordinary speech and paragraphs which contain stage comments such as interjections.
Additional Remarks
Like most of this documentation, this section focuses on the Corpus Workbench version of the GermaParl v2 corpus. The XML/TEI version of the corpus also contains the annotation of agenda items. Since these annotations are rather experimental, they are not included in the current version of the CWB corpus. Section 3.4.3 on the consolidation of the corpus provides some insights into the preparation of the agenda item annotation.
The CWB corpus data model is described in more detail by Stephanie Evert and the CWB Development Team in the corresponding online documentation of the Corpus Workbench (https://cwb.sourceforge.io/documentation.php, last accessed on 2023-01-04). See in particular https://cwb.sourceforge.io/files/CQP_Manual/1_2.html (last accessed on 2023-01-04).↩︎