by Andreas Blätte
A new GermaParl v2 beta version to improve usability
On May 23 last year (Germany’s Constitution Day), we released the first beta version of GermaParl v2, a major rework of the GermaParl Corpus of Plenary Protocols of the German Bundestag. The most obvious development is that v2 comprises all protocols of plenary sessions in the German Bundestag (1949 - 2021). But there is also a change of the data structure. The “flat” scheme of structural attributes of GermaParl v1 had its merits for the usability of the data, but increasingly brought limitations. It inhibits performance and flexibility to handle nested attributes and annotations. The growth of the corpus as well as the inclusion of further annotation layers (sentence annotation and named entities to start with) induced us to move to a more hierarchical representation of the data with GermaParl v2.
Yet the feedback we received from (beta) users on the 2022 beta versions of GermaParl v2 confirmed a suspicion: The data structure of GermaParl v2 was not yet sufficiently intuitive. So to improve the usability of the data, we somewhat reworked the data structure. The new beta release (GermaParl v2.0.0-beta.3) now available at Zenodo addresses usability issues. This release note explains how the data structure has changed and how to use it.
Getting started with GermaParl v2.0.0-beta.3
The landing page of GermaParl v2.0.0-beta.3 at Zenodo explains how to register as a beta user and how to install the corpus using the ‘cwbtools’ package.
Using the more hierarchical data structure of GermaParl v2 requires changes of the packages used for analysing the data. In the background, the RcppCWB package has been developed stepwise to meet these requirements. Using the reworked data structure of GermaParl v2 requires the most recent release of the polmineR package: Installing the latest version (v0.8.8), recently published at CRAN is a prerequisite to leverage the potential of the new beta release. Install it if necessary, and load it.
if (packageVersion("polmineR") < numeric_version("0.8.8"))
install.packages("polmineR")
library(polmineR)So this is new
The differences between the current and the previous beta release of GermaParl v2 are somewhat technical. Contrasting GermaParl v1 and GermaParl v2 may be the best entry point to explain what is new: GermaParl v2 moves beyond the deliberately “flat” data structure of GermaParl v1: The XML indexed as a corpus using the Corpus Workbench (CWB) functionality now maintains the logic that plenary protocols are the basic unit of data preparation. Information at the level of plenary protocols (date, legislative period, session number) is now maintained at this level, and is not turned into speech/speaker-level attributes as previously. The data structure with a hierarchy of plenary protocols, speakers, paragraphs, sentences and named entities (spans of words within sentences) can be visualized as follows.
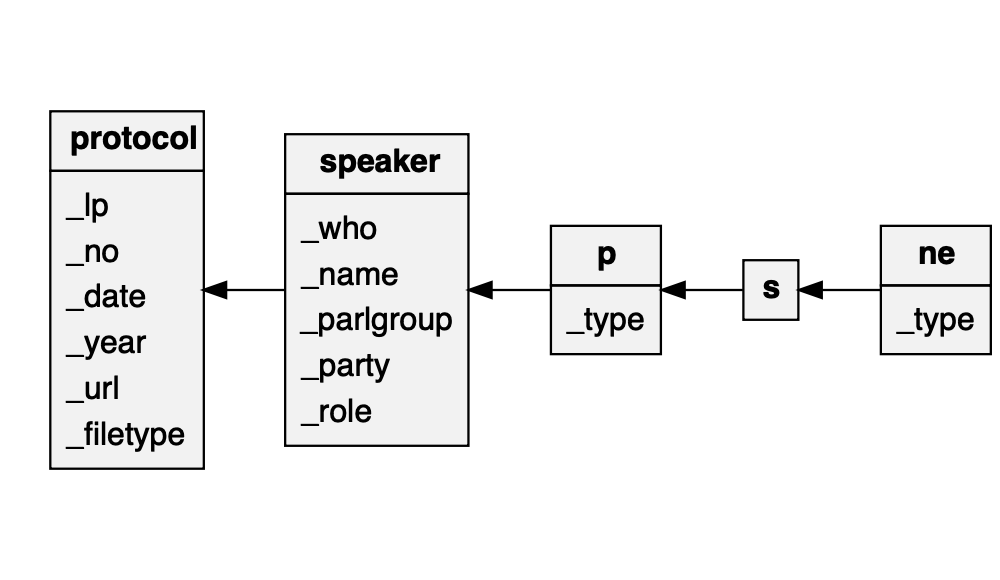
The hierarchy of the data structure was somewhat concealed by GermaParl v1 and the previous beta release of GermaParl v2. The naming of structural attributes was kept as short as possible, removing information about the structure of the data. The recent GermaParl v2 release maintains this information and makes it explicit: The names of structural attributes now combine the XML element name and XML attribute names, pasted with an underscore. The following mapping table shows, how structural attributes of GermaParl v1 now correspond to structural attributes of GermaParl v2.
| GermaParl v1.0.6 | GermaParl v2.0.0-beta3 |
|---|---|
| lp | protocol_lp |
| session | protocol_no |
| date | protocol_date |
| year | protocol_year |
| src | protocol_filetype |
| url | protocol_url |
| agenda_item | agenda_item_type |
| speaker | speaker_name |
| party | speaker_party |
| parliamentary_group | speaker_parlgroup |
| role | speaker_role |
| interjection | p_type |
What is more: As we learned from users’ feedback, the previous beta version of GermaParl v2 maintained the “original” data structure of plenary protocols concerning interjections, but made it hard to handle. Interjections were XML children of speeches - making it difficult to exclude them from the analysis of speeches. But this is obviously necessary, if you want to analyse speech-making. Our practical solution now is to model interjections and stage instructions as distinct types of paragraphs within speeches. The introduction of the structural attribute p_type is the precondition for subsetting subcorpora of speeches to exclude interjections.
The following table conveys the full picture how the naming of s-attributes has changed between GermaParl v2.0.0-beta.2 and GermaParl v2.0.0-beta.3.
| GermaParl v2.0.0-beta.2 | GermaParl v2.0.0-beta.3 |
|---|---|
| plenary_protocol | protocol |
| lp | protocol_lp |
| protocol_no | protocol_no |
| date | protocol_date |
| year | protocol_year |
| url | protocol_url |
| filetype | protocol_filetype |
| speaker_node | speaker |
| who | speaker_who |
| speaker | speaker_name |
| parpiamentary_group | speaker_parlgroup |
| party | speaker_party |
| role | speaker_role |
| stage | [not available] |
| stage_type | [not available] |
| p | p |
| [not available] | p_type |
| s | s |
| ner | ne |
| ner_type | ne_type |
The information, whether tokens are part of a speech or of an interjection reported in stage instructions is now part of the annotation of paragraphs. The structural attribute “p_type”, which assumes the values “speech” and “stage”, can now be used to subset a corpus to keep speeches and to drop interjections. See the following sample code.
by_name <- corpus("GERMAPARL2") %>%
subset(p_type == "speech") %>%
subset(speaker_name == "Angela Merkel")The polmineR package has been extended and reworked to be able to process the nested XML structure. The subset() method for corpus and subcorpus objects has been introduced to offer much more flexibility for working with nested data structures. The most important difference with subset() for corpus/subcorpus objects is that non-standard evaluation can be used in a way widely used in the tidyverse. Consider the following example how this is useful.
by_date <- corpus("GERMAPARL2") %>%
subset(p_type == "speech") %>%
subset(as.Date(protocol_date) > as.Date("2001-09-11"))One final point: The ability to display the full text of parliamentary speeches is a unique feature of polmineR. As things stand, it is necessary feed a paragraph-based (s-attribute p) definition of a subcorpus into read() to be able to display the full text with formatted interjections - see the following example.
speeches <- corpus("GERMAPARL2") %>%
subset(protocol_date == "2001-09-12") %>%
subset(p) %>%
as.speeches(
s_attribute_date = "protocol_date",
s_attribute_name = "speaker_name"
)
speeches[[1]] %>% read()Where to go from here
This release note has a focus on the changes of the data structure of the new beta release of GermaParl v2 and how to use it with the polmineR package. Certainly, many users will consider the historical breadth of the data to be the most interesting aspect of GermaParl v2. But if the data is not modeled adequately and usable at the same time, analytical usage will be inhibited. As GermaParl v2.0.0-beta.3 is now available, we will be happy to receive further feedback that we can address by either improving the data, or the documentation.
Our further release plan for GermaParl v2 now is as follows:
-
A final beta release (#4) of GermaParl v2 is scheduled for late April 2023. This upcoming (last) beta version will improve data quality and offer extended documentation.
-
We plan to officially release GermaParl v2 on this year’s Constitution Day, on May 23. Data structure, data quality and documentation shall then be consolidated to meet the requirements of a wider audience. The data will then be available without the need to register as a beta user.
The release of GermaParl v2 in May will be the starting point of further quality improvements based on user feedback. But full disclosure: In the context of our contribution to the Text+ consortium as part of Germany’s Research Data Infrastructure (NFDI), we are already working on an XML version of GermaParl that will then be based on the ParlaMint standard (upcoming GermaParl v3). And in the Kontext of KonsortSWD, which is also part of NFDI, we will use GermaParl as public sample data for entity linking. So GermaParl v2 is an intermediate step - but an important one.
Subscribe via RSS