by Andreas Blätte
Vector representations for words are becoming popular in text mining. In particular, the text2vec algorithm (by Tomáš Mikolov) and the GloVe algorithm (by Jeffrey Pennington, Richard Socher and Christopher D. Manning) have attracted considerable attention - including mine.
These algorithms generate a vector representation of words based on term cooccurrence matrices. Word vectors capture the semantics of a word based on its neighborhood in a low-dimensional fashion. This is an appealing intuition. There is a wealth of use cases that go beyond the relatively basic scenario I explore here: Are vector representations for words useful for getting the vocabulary of a semantic field?
The corpus I use is the most recent beta version of the corpus of plenary protocols (1994-2016, 105 M words). Unsurprisingly, I use the polmineR package to access the corpus. I will then continue with the GloVe implementation included in the text2vec package, a package I have come to admire. Using text2vec would be an attractive, fast alternative - but I was interested in a pure R take on word vectors. The examples I finally use to explore semantic fields are taken from my substantive field of interest, migration and diversity in German politics.
Getting started
To get started, I load the polmineR package, and the data.table package which I will use later on.
library(polmineR)
library(data.table)
use("plprbt")The vocabulary of interest
Very rare words will not be interesting. We perform a word count for the corpus (PLPRBT), and discard all words that to not occur at least 10 times.
PLPRBT <- Corpus$new("PLPRBT")
PLPRBT$count(pAttribute = "word")
vocabulary <- PLPRBT$stat[count >= 10][["word"]]Lately, I have really spent a lot of time cleaning my corpus of parliamentary debates. It is however still necessary to get rid of noise.
vocabulary <- vocabulary[-which(vocabulary %in% unlist(noise(vocabulary)))]The resulting vocabulary includes 112462 tokens. Being more conservative and applying a higher minimum word occurrence threshold would have been possible. Yet I want to suffer. To test performance, I did not want to keep object sizes minimal here.
Generating the term cooccurrence matrix
The GloVe algorithm will require a term cooccurrence matrix as input. I am somewhat proud in that respect: In the most recent version of the polmineR package (dev branch on GitHub), I have introduced a cooccurrences method for character class objects that will generate the term cooccurrence matrix for a whole corpus in a somewhat optimized manner.
PLPRBT_tcm_slam <- cooccurrences("PLPRBT", keep = vocabulary, window = 10)On my laptop (a Macbook Pro, 256 GB SSD, 2,6 GHz i5), getting the term cooccurrence matrix for the 105 M corpus takes 10 minutes. No doubt, an optimized C implementation will be much faster. For me, at this stage, I do not mind waiting 10 minutes.
There is a technical detail to take care of. The cooccurrences method returns a sparse matrix (of class ‘simple triplet matrix’). The GloVe class requires a ‘dgTMatrix’ as an input, one of the classes defined in the Matrix package (a compressed, sparse, column-oriented format). The as.sparseMatrix method in the polmineR package will generate a ‘dgCMatrix’. From that point, a coerce method defined in the Matrix package can be used.
PLPRBT_tcm_dgCMatrix <- as.sparseMatrix(PLPRBT_tcm_slam)
PLPRBT_tcm_dgTMatrix <- as(PLPRBT_tcm_dgCMatrix, "dgTMatrix")Now, we a few big and bulky objects in memory. When working on this post, I was not always very cautious and I ran out of memory (16 GB) several times. To avoid this, objects that are no longer needed can be removed.
rm(PLPRBT_tcm_slam, PLPRBT_tcm_dgCMatrix)Running GloVe
The text2vec package strives to be particularly fast at generating anything you need for bag-of-words-operations text files. It is not that part of the functionality I really need. Yet I was really happy to discover that the text2vec package includes an implementation of the GloVe algorithm. After initializing the class, we can run the global vectors algorithm.
library(text2vec)
GV <- GloVe$new(
word_vectors_size = 50, vocabulary = rownames(PLPRBT_tcm_dgTMatrix),
x_max = 10, learning_rate = .1
) # in example learning_rate .25
GV$fit(x = PLPRBT_tcm_dgTMatrix, n_iter = 25)I may be running more iterations than necessary. Getting the word vectors as described takes 10 minutes. Having run the fitting algorithm, I can get the matrix with word vectors - the object of desire!
glove_word_vectors <- GV$get_word_vectors()There are many useful things you can do with word vectors. For instance, I have played with word vectors for calculating sentence similarity. Here, I wish to keep it simple by working with word similarity.
Dictionaries and semantic fields: A first take
Word vectors can be used to find similar words to a query by calculating the cosine similarity of the vector for the query with the vectors of all other words. The result may be considered the vocabulary of a semantic field.
To assist running that operation not just once, let us prepare a small convenience function that will calculate the cosine similarity, put the result in a data.table, merge in word counts, order the result based on cosine similarity, and return just the top n words.
get_semantic_field <- function(query, n = NULL, count = PLPRBT$stat){
query_vector <- matrix(glove_word_vectors[query,], nrow = 1)
similarities <- proxy::simil(x = glove_word_vectors, y = query_vector, method = "cosine")
similarities_dt <- data.table(word = rownames(similarities), cosine = similarities[,1])
setkeyv(similarities_dt, cols = "word")
similarities_dt <- count[similarities_dt]
setorderv(similarities_dt, cols = "cosine", order = -1)
similarities_dt <- similarities_dt[2:nrow(similarities_dt),]
if (!is.null(n)) similarities_dt <- head(similarities_dt, n = n)
similarities_dt
}Results
So, we are ready to get results for three keywords in Germany’s debates on migration and integration (“Zuwanderung”, “Asyl”, “Islam”). Although word clouds are always very illustrative, I prefer Cleveland dot plots as a simlple visualisation, as they convey information in a very intuitive manner.
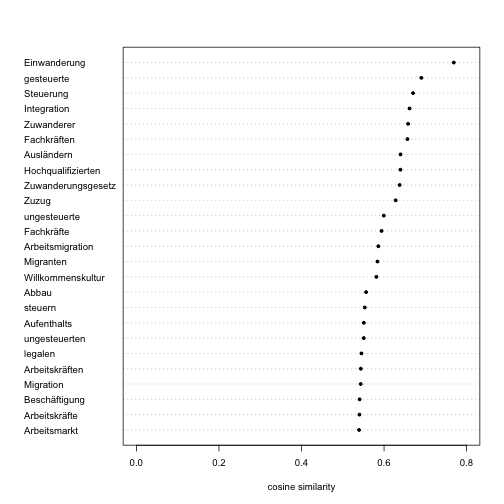
Zuwanderung
zuwanderung <- get_semantic_field("Zuwanderung", 25)
dotchart(
x = rev(zuwanderung[["cosine"]]),
labels = rev(zuwanderung[["word"]]),
pch = 20, cex = 0.8, xlim = c(0, 0.8),
xlab = "cosine similarity"
)
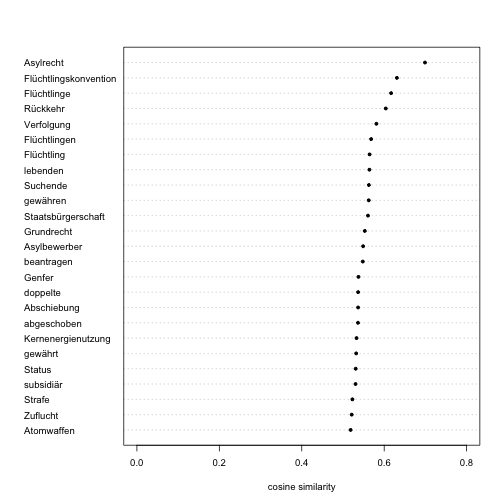
Asyl
asyl <- get_semantic_field("Asyl", 25)
dotchart(
x = rev(asyl[["cosine"]]),
labels = rev(asyl[["word"]]),
pch = 20, cex = 0.8, xlim = c(0, 0.8),
xlab = "cosine similarity"
)
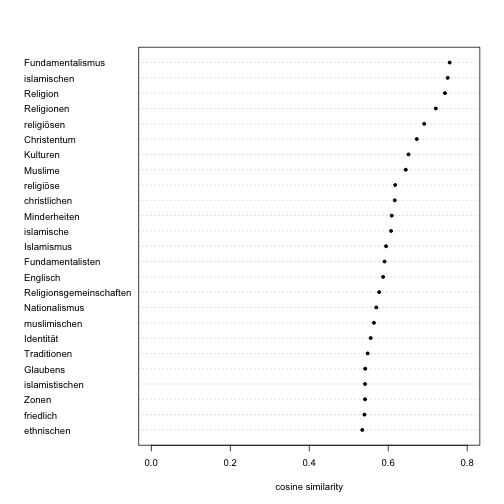
Islam
islam <- get_semantic_field("Islam", 25)
dotchart(
x = rev(islam[["cosine"]]), labels = rev(islam[["word"]]),
pch = 20, cex = 0.8, xlim = c(0, 0.8),
xlab = "cosine similarity"
)
Discussion
Admittedly, non-German speakers will not be able to assess the results of this exercise. (I wanted to use Google’s translation API to get English translations, but I could not get my key work.) But it’s true! The result is very intuitive. Among the words similar to ‘Asyl’ (asylum), we find two terms referring to nuclear energy as hits. It might be caused by a word neighbourhood indicating a similar degree of controversy - but this is a speculation, so far. Still, we have very good reasons to seriously consider vector representations of words to generate semantic fields.
There is much more that can be done with word vectors. As of today, I am satisfied with the results, which convey the usefulness of this analytical technique. Importantly, it also demonstrates that there is a smooth path from a CWB corpus accessed with the polmineR package to a term cooccurrence matrix that can be processed with the GloVe class in the text2vec package.
This is an updated version of the original post. Thanks to Christopher Smith for his useful feedback!
Subscribe via RSS