by Andreas Blätte
Towards polmineR v0.8.0: A new annotation workflow
The polmineR package strives to offer a basic programming vocabulary to implement workflows for complex text analytical tasks, including annotation. The basic requirements for this, i.e. the ability to reconstruct (passages of) full text at any time has always been there, but the annotation functionality has been an unfullfilled promised. As we are approaching v0.8.0, the idea to realize an annotation workflow shall finally materialize.
In this blog post, I would like to introduce a new workflow to annotate classes inheriting from the textstat class, such as an analysis for keywords-in-context (kwic) or of cooccurrences. It is available in its current form starting from polmineR version 0.7.11.9023, available on the development branch of polmineR at GitHub. It can be installed as follows (if you have the devtools package installed):
devtools::install_github("PolMine/polmineR")The impetus for developing the functionality came from using a dictionary to score the degree of populism in parliamentary speeches. But using dictionaries comes with a risk. The validity of measurements using dictionaries can not always be taken for granted, given the ambiguity of terms. This is the idea that suggests itself: For annotation and disambiguation, it would be nice to have a simple and efficient “pure R” workflow, i.e. we do not want to leave the R session we are using for the rest of our analysis of corpora and further data.
To keep things simple, the scenario I use here is a simple effort to disambiguate (the German word) “Integration”. Fairly often, it is used to refer to the integration of immigrants into society. But there are other relevant contexts with a different meaning. You can also talk about the integration of unemployer persons into the labour market, or of handicapped persons into society. Thus, let us assume we want to count the number of occurrences of “Integration” in the context of migration and integration affairs and that we want to avoid counting the occurrence of “Integration” in other contexts.
This disambiguation might also be achieved through a rule-based procedure (i.e. a dictionary of words required to occurr in the neighborhood of our match, and/or a dictionary preventing a match to be counted), or a procedure based on training data. But to develop either approach, manual inspection and annotation may be necessary as a first step anyway. So this is why we need a workflow for manual annotation. Once we have it at hand, we can also use it for a brute-force manual annotation from dusk till dawn for all matches without further sophistication. At times, this appraoch may not be the worst one from the “know your data” and validity point of view.
The solution polmineR is now able to offer is a shiny gadget that uses the Handsontable JavaScript library which is exposed through the rhandsontable package. When you start the gadget in an RStudio session, it will be shown in the Viewer pane of RStudio, and you will have the results of your annotation exercise in the R sessions right away, without having to export data and switching applications. The following animated gif may convey the essence and the look and feel of this new feature.
Now for the more verbose explanation how to use the new functionality, including the code. We start by loading polmineR and activating the GERMAPARL corpus of parliamentary debates in the German Bundestag.
library(polmineR)
use("GermaParl") # activate GERMAPARL corpusThen we generagte a kwic object using the kwic()-method. Pursuing the scenario introduced before, we look up matches for “Integration” in the GERMAPARL corpus.
x <- kwic("GERMAPARL", query = "Integration")The resulting object x has used the default left and right context of 5 tokens. Often, we will find that we may want to see more words to solidify our annotation decisions. For this, we use a new argument of the enrich()-method to get us an extra 5 words to the left and to the right of our search windows.
x <- enrich(x, extra = 5)When kwic objects are generated and enriched, a data.table in the slot stat of the object is filled with the concordance lines. This table can be augmented with a new column as follows. In our example, we add a (logical) column called “mi” (for migration and integration) to indicate whether our match for “Integration” occurrs in a migration and integration context.
annotations(x) <- list(name = "mi", what = TRUE)Note that you can also add columns with a character vector, or a factor. Assigning a factor can be a good choice, when you want to offer users or yourself a limited set of choices. One of the beauties of basing the shiny widget on the Handsontable library for html spreadsheets is that for factor columns, a drop down menu is used for data input by default. See the examples for the annotation functionality (?annotations) to see an example.
Now we have a kwic object with the annotation layer we just added. We can use the edit() method to call the shiny gadget we have been talking about and that you could see in the initial animated image.
edit(x)Once you call the edit()-method, the gadget pops up in the RStudio Viewer pane, and you can edit the annotations (here: the “mi”-column) as you wish, in a manner you would know from a conventional spreadsheet program such as Excel.
Once you finished editing annotations, click the “Done”-button, and the results of the annotation effort are available in the R session. You can get the data.table with the annotations by calling the annotations()-method on the annotated object.
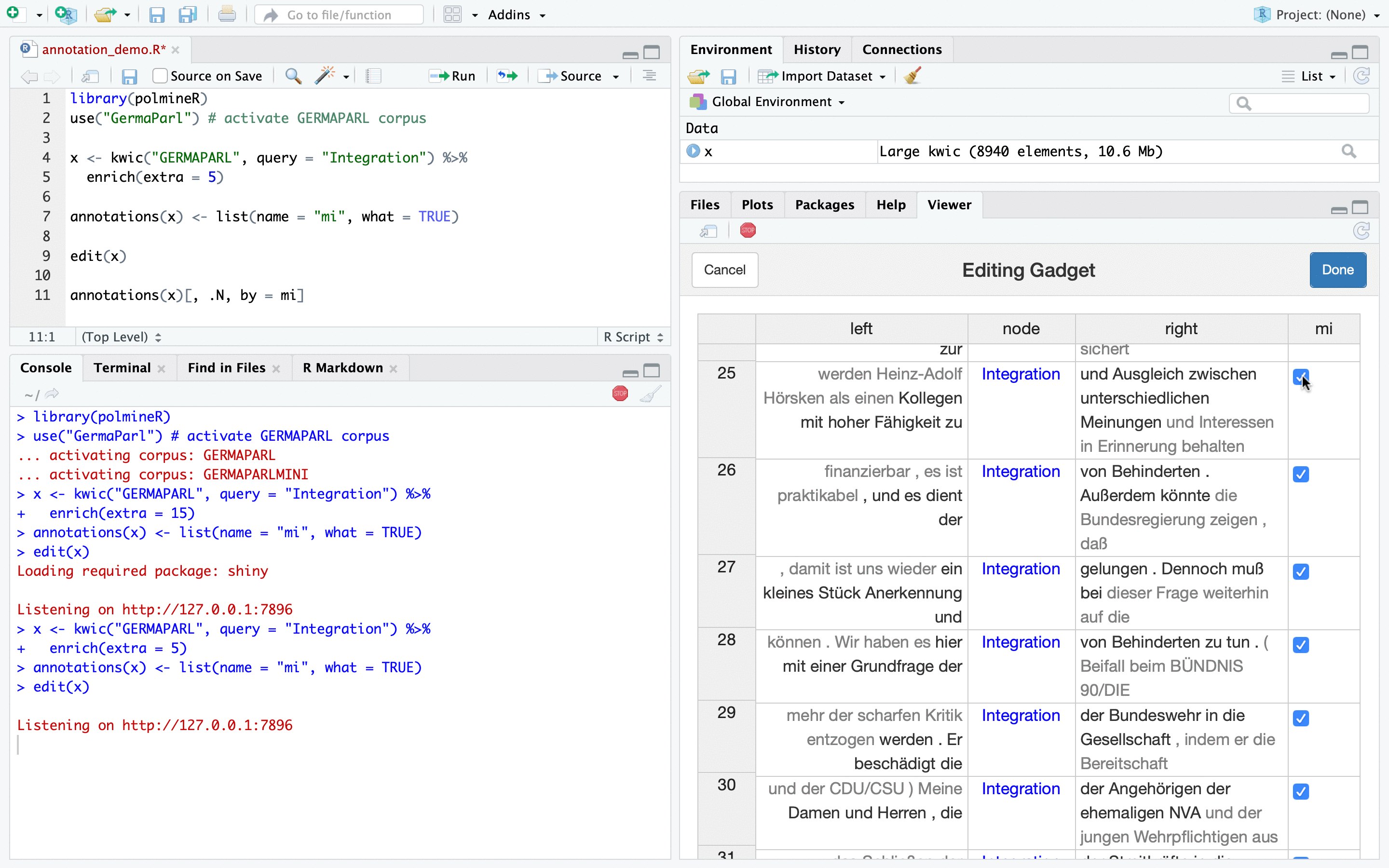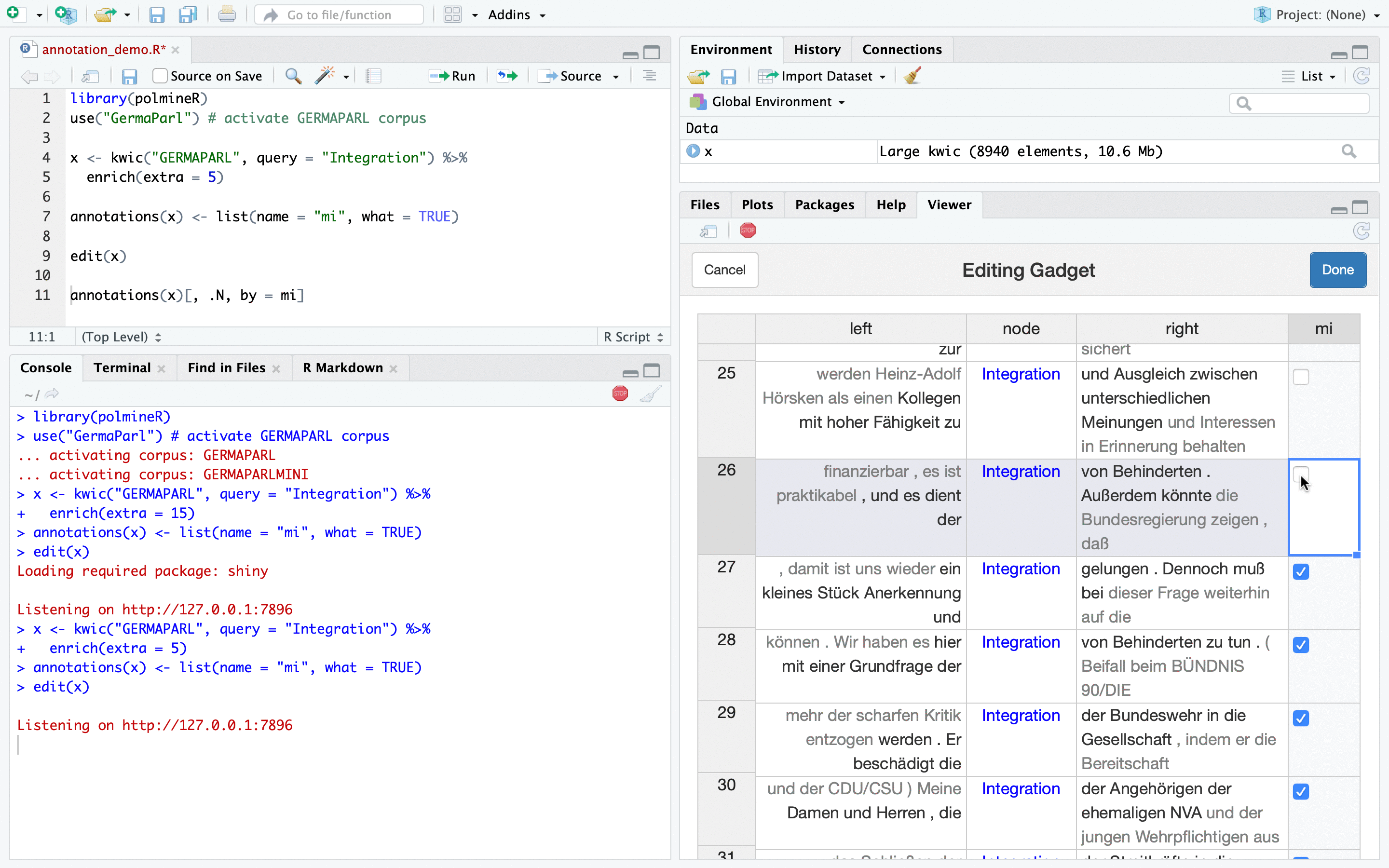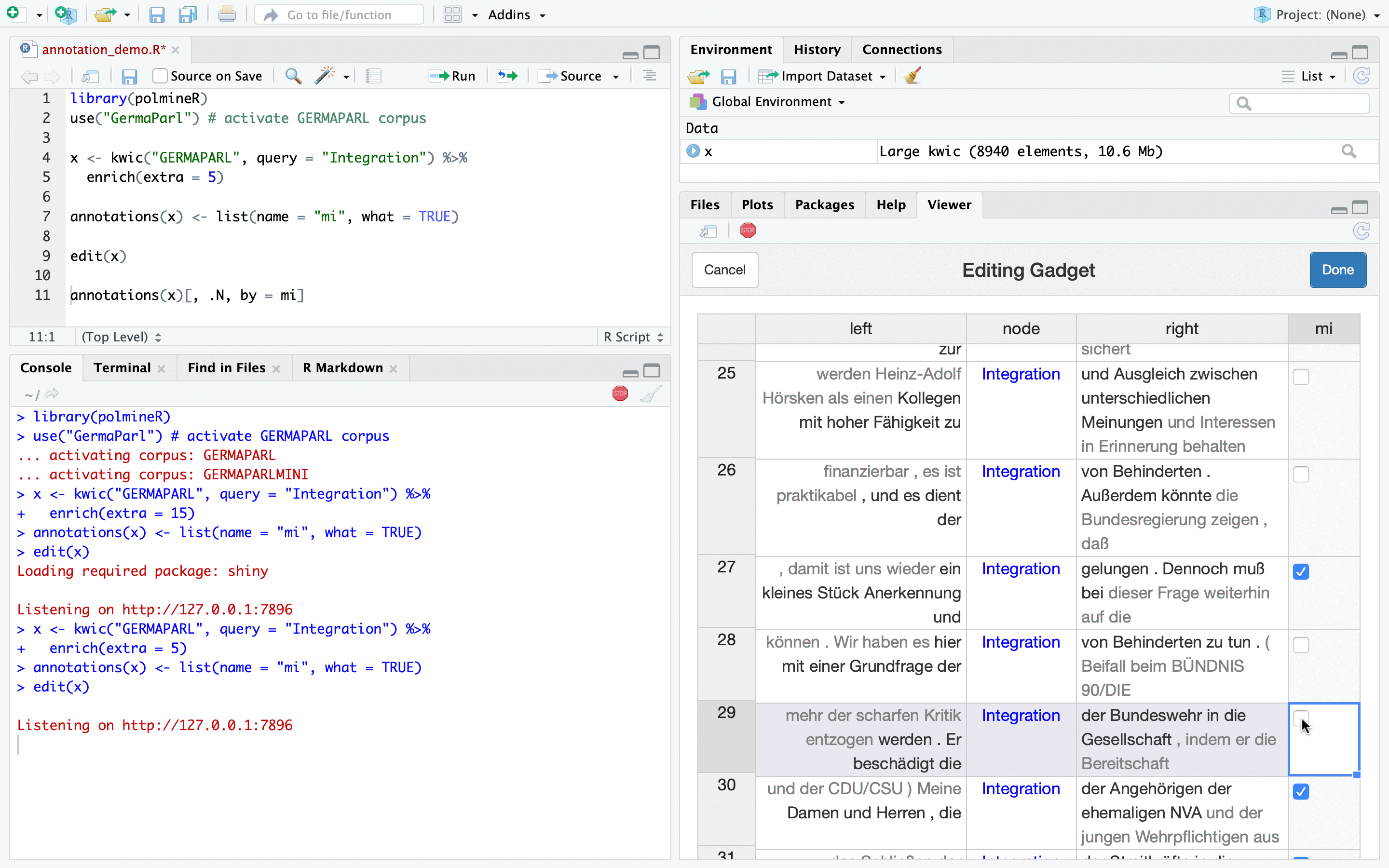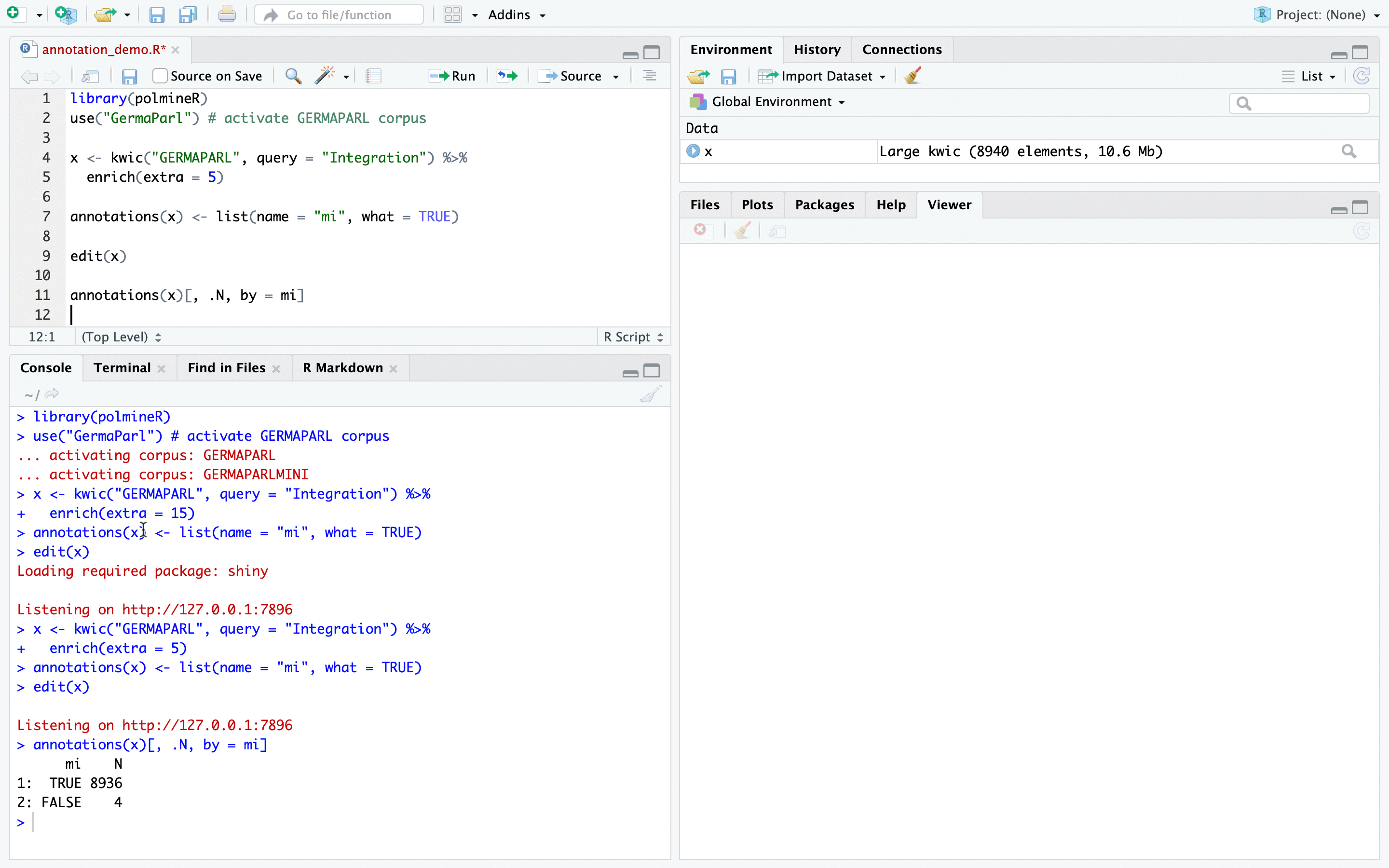
annotations(x)And of course, you can aggregate the result. For instance, to count the number of TRUE/FALSE classifications, use the notation of the data.table-package to aggregate results for the column “mi”.
annotations(x)[, .N, by = mi]Having gone through our kwic object, the real work in our analysis to obtain a substantive result will usually only start. For instance, if the aim was just do get rid of false matches, use the subset()-method on the kwic object to discard the matches we have annotated with FALSE.
x_min <- subset(x, mi == TRUE)
length(x_min) # see the length of the shortened objectQuite obviously, it may be tedious to go through concordances if we have a large number of matches. It may be very attractive to use a limited set of annotated lines as training data. For most ML exercises, we will need a Document-Term-Matrix. You get it as follows…
dtm <- as.DocumentTermMatrix(x, p_attribute = "word")And we have the labels for the algorithm at hand, recall that we can get it by calling annotations(). But explaining how to do the machine learning part goes beyond this post: The aim here has been to introduce the new annotation workflow of the polmineR package.
Just a final remark: You can annotate and edit any object that inherits from the textstat-class. Apart from annotating kwic-objects, annotating cooccurrences may be an important use case.
I hope you find the new annotation functionality useful. Feedback is welcome!
Subscribe via RSS