by Andreas Blätte
Towards polmineR v0.8.0: Pipes ahead
As I work towards the v0.8.0 release of the polmineR package, I have introduced two new classes (corpus and subcorpus), and a somewhat new workflow to work with corpora and subcorpora. It shall eventually replace the known usage of the partition()-method and the partition-class. So what is new, in a nutshell? Subcorpora are now obtained from corpora using the subset()-method.
In this blogpost, I will explain and discuss this intervention in the vocabulary of polmineR. There are several aims associated with introducing two new classes corpus and subcorpus, and specifying the subset()-method for these classes. It shall…
- make the vocabulary of the polmineR package more intuitive;
- integrate the use of pipes seamlessly in analytical workflows;
- make the class system of the package more coherent;
- be the basis to work with remote corpora;
- bring some performance improvements as a goodie.
The new workflow is available in the new versions of polmineR on the development branch of the repository at GitHub. It can be installed as follows.
devtools::install_github("PolMine/polmineR", ref = "dev")In the following examples, I will use the GermaParl corpus of plenary protocols of the German Bundestag. We activate the corpus after loading the polmineR package as follows.
library(polmineR)
use("GermaParl") # activate GERMAPARL corpusThe new workflow: A short demo at the outset
Before going into verbose explanations, a short example shall convey the look and feel of what is new. The “old” vocabulary and workflow of the polmineR package relies on the creation of a partition object using the partition()-method to work with subcorpora. For those who have already used polmineR, the following code will look familiar. If you want to count the number of occurrences of “Finanzkrise” in speeches given by Angela Merkel in the Bundestag in 2008, this is what we used to write:
merkel2008 <- partition(
"GERMAPARL",
speaker = "Angela Merkel",
year = "2008",
verbose = FALSE
)
count(merkel2008, query = "Finanzkrise", verbose = FALSE)## query count freq
## 1: Finanzkrise 3 0.0001143554This workflow is now superseded by a combination of an explicit definition of a corpus-class using the corpus()-method as a constructor, and a subset()-method that is defined for corpus and subcorpus objects. Using the pipe operator (“%>%”) of the magrittr-package has been supported before, but the new workflow is deliberately designed to work with pipes. The previous example would now be written as follows.
corpus("GERMAPARL") %>%
subset(speaker == "Angela Merkel") %>%
subset(date == "2008-11-26") %>%
count(query = "Finanzkrise", verbose = FALSE)## query count freq
## 1: Finanzkrise 2090 0.3273297So why do I think, this is a improvement? Let me go into the five aims of the refactoring exercise.
Aims of refactoring polmineR
From partitions to subcorpora: A more intuitive vocabulary
First and foremost, I want to make the vocabulary and the workflows of the polmineR package as intuitive as possible. My sense is that having the subcorpus-class supersede the partition class and using the subset()-method to create subcorpora from corpora will serve this purpose.
When I started writing tutorials for polmineR last year (i.e. the “Using Corpora in Social Science Research” set of slides), an issue that had bothered me before re-occurred to me: Explaining why the partition-class is called “partition”, and why the polmineR terminology opts for using the partition()-method to create a subcorpus is clumsy. The naming of the partition class again and again required me to write at least one extra sentence. Something like this: “In the polmineR context, I call a subcorpus a ‘partition’ in line with language established in the French lexicometric tradition.” The French lexicometric tradition is still as rich and admirable as it has always been, but at the end of the day, the extra sentence is cumbersome. It is easier to just call a subcorpus a subcorpus.
In fact, I had refrained from defining a subcorpus class a couple of years ago to avoid a namespace conflict with the rcqp package which included a subcorpus-class. But as the former rcqp package has been superseded by the RcppCWB package, this potential namespace conflict has ceased to exist. So the partition()-method can be replaced by a subset()-method defined for corpus- and subcorpus-objects. You now derive a subcorpus from a corpus by subsetting the corpus. My sense is that this is more intuitive, and you can explain workflows in a straight-forward manner, without the explanatory detours I have mentioned.
Subsetting (sub)corpora: A more intuitive workflow using pipes
The new workflow that combines the corpus/subcorpus class and the subset()-method is designed to work with pipes that have been popularized in the context of the “tidyverse”, and with the dplyr-package in particular.
To count the number of occurrences of “Finanzkrise” in speeches given by Angela Merkel in the Bundestag, the extensive, “classic” code would be as follows.
gparl <- corpus("GERMAPARL")
merkel <- subset(gparl, speaker == "Angela Merkel")
merkel_fincris <- count(merkel, query = "Finanzkrise", verbose = FALSE)To avoid defining variables you might not need later on and that will spam your global environment, you might write this one-liner.
count(
subset(
corpus("GERMAPARL"),
speaker == "Angela Merkel"),
query = "Finanzkrise",
verbose = FALSE
)## query count freq
## 1: Finanzkrise 36 5.13219e-05Quite obviously, this is not particularly easy to read. Using a pipe results in code that is much easier to digest.
corpus("GERMAPARL") %>%
subset(speaker == "Angela Merkel") %>%
count(query = "Finanzkrise", verbose = FALSE)## query count freq
## 1: Finanzkrise 36 5.13219e-05Notably the dplyr package that imports the magrittr pipe operator by default has popularised by the usage of pipes. With good reasons. Pipes are not a good idea within packages, but great for developing an analysis. Using pipes helps to organise the code of your analysis cleanly.
To prepare using pipes in analyses using polmineR by default, the package now imports the operator the same way dplyr does: Once you load polmineR, the pipe operator is available. I encourage polmineR users to use pipes, and I started using pipes in the examples in the documentation.
Subsetting (sub)corpora: The flexibility of non-standard evaluation
The move from the partition()-method to the subset()-method to create subcorpora entails that non-standard evaluation (NSE) can now be used to define subcorpora. I gratefully admit that this idea was suggested originally by Christoph Leonhardt in a GitHub issue. For defining subcorpora, you can now use logical operators, and actually anything you know from subsetting a data.frame. (Note that the object resulting from subsetting a corpus will not be a data.frame!).
You can now write expressions that will feel well-known natural for R users. The specialized yet limiting syntax of the partition()-method can be overcome. Consider the following examples.
merkel <- corpus("GERMAPARL") %>% subset(speaker == "Angela Merkel")
merkel <- corpus("GERMAPARL") %>% subset(grep("Merkel", speaker))
merkel <- corpus("GERMAPARL") %>% subset(speaker == "Angela Merkel" & year == "2008")
cdu2008 <- corpus("GERMAPARL") %>% subset(year == "2008") %>%
subset(party == "CDU") %>%
subset(role != "presidency") %>%
subset(interjection == "FALSE")
cdu_lp17 <- corpus("GERMAPARL") %>%
subset(lp == "17" & party == "CDU" & role %in% c("mp", "government"))The corpus and the subcorpus class: A more coherent class system
This is a more technical consideration that requires a basic knowledge of object-oriented programming (OOP), but it will be important for the long-term development of polmineR: An aspect of the partition class that had disturbed me for a while was that it is actually a hybrid class serving two purposes at the same time.
The partition class inherits from the elementary teststat superclass. The textstat class is the mother of all classes that keep statistical information derived from corpora or subcorpora in a slot called stat. Generic methods such as nrow(), round() or sort() are defined for the texstat class. So you have lots of additional functionality available for classes inheriting from the textstat class (such as the partition class) without extra programming effort.
But the main purpose of the partition-method is actually to organise information on the definition of a subcorpus. In addition, it could be used to store an evaluation of counts. But the count-class is already there for count statistics, and specialized for this purpose. Even though there is still a case for keeping the partition class, it is much more logical to keep the management of corpora and subcorpora, and of statistical evaluations seperate. So the solution now is that we have an elementary corpus class, and a subcorpus class that inherits from it.
The introduction of the corpus class is something like a side-effect of cleaning up the structure of classes of the package. But I think it will help to make code more expressive and robust. It changes the way we work with corpora somewhat. Traditionally, we wrote
s_attributes("GERMAPARL")Now you should write…
corpus("GERMAPARL") %>% s_attributes()This is somewhat longer, yet more expressive. What is more, the constructor for the corpus class, the corpus()-method, can now perform a set of standard checks for the input, such as checking that all letters of the corpus id are uppercase.
The door is open: Working with remote corpora
There is an even more substantial advantage of the introduction of the corpus class. The refactoring of the class system opens the door to implement a remote_corpus class to manage information on a corpus that is not stored locally, but on a remote server. The implementation I have in mind is a server that runs OpenCPU. This is already implemented experimentally, see the documentation for the corpus()-method (?corpus), the argument server in particular.
A corpus stored locally will almost always be the fastest option. But at times, you may want to omit downloading a large corpus. More importantly, there is a significant set of scenarios when licenses actually prohibit transferring a corpus. Working with a remote corpus that is not transferred may be part of the solution. Explaining and illustrating this in detail goes beyond this post. An upcoming blogpost shall explain how you can work with remote corpora.
Subsetting corpora: Faster than creating partitions
A final goodie: Creating subcorpora from corpora using the subset()-method is faster than creating a partition. If we create a partition/subcorpus of the GERMAPARL corpus a couple of times (five times here), the new subsetting-procedure takes on average only half of the time compared to the old procedure. See the following basic benchmark.
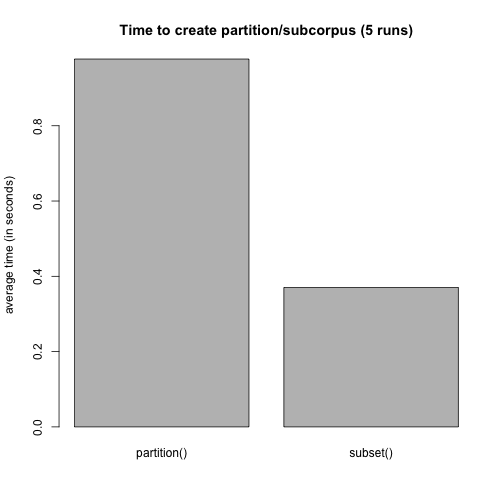
The performance improvement results from a new procedure for decoding structural attributes for an entire corpus. Note that the improvement will be more limited if you subset an existing subcorpus. Nevertheless: Subsetting an entire corpus is a significant scenario, and cutting the time consumed by 50% is substantial.
Discussion
The presented intervention in the polmineR package is non-trivial and significant. While many aspects are uncontroversial (I guess nobody will dislike a performance increase), I would like to two address aspects that are more disputable.
-
The introduction of the
corpusclass comes at a cost: The quanteda package also defines a class with the same name. The polmineR package uses the S4 class system, quanteda uses S3, but both packages use the same constructor, thecorpus()-method. If you load the polmineR package after having loaded quanteda, or vice versa, there will now be a warning on a namespace conflict. This is far from ideal, as the quanteda package includes important analytical functionality polmineR users may want to use. Having thought about the pros and cons, I thought the namespace conflict may be bearable: First of all, there is no substantial problem beyond the warning issued, if you use polmineR to evaluate a corpus and quanteda for there further analytics. Second, the solution to omit defining thecorpus()-method in polmineR would have violated the aim to establish a new naming of classes/methods that is as intuitive as possible. -
Another question was whether using the
subset()-method might not provoke the misunderstanding that the result would be adata.frame. Indeed, I had worked with azoom()-method experimentally. But when moving from a corpus to a subcorpus, it is not actually a “zooming in”-operation that is performed. If you extract the speeches given by Angela Merkel, for instance, these passages of speech are scattered across many protocols. So the term “zoom” will not capture well what you actually do (thanks to Max Hugendubel and Stefan Haußner for their thoughtful input on this!). So I do not think that that omitting usage of thesubset()-method is the solution, but documenting and explaining the workflow within the package is what matters.
Roadmap
Introducing the new workflow is not a small intervention. Fully consolidating the code and updating the documentation is yet to be accomplished. It will still take some time: I plan to relase v0.8.0 this summer (July/August) once all known bugs are removed and when having reworked the documentation.
Given the size of the intervention, I do not want to deprecate the old workflow prematurely:
- In v.0.8.0, the “old” workflow (that uses the
partition()-method) will remain fully intact. - v0.9.0 will issue warning messages that the old workflow is deprecated.
- Only with v1.0.0 I will clean up the code and remove functionality that will then knowingly be defunct.
Acknowledgements
I gratefully acknowledge the feedback of Christoph Leonhardt on many questions I had whether the new workflow is more intuitive. A discussion with the text mining group of my department at the University of Duisburg-Essen encouraged me to finally advertise the changes made with this blogpost, thanks for the debate and feedback!
Subscribe via RSS