by Andreas Blaette
The case for biglda: Topic modelling benchmarks
As I picked up developing the biglda R package again (a GitHub-only package, see dev branch here), I started to wonder: Is this is really worth the effort? Pleasure and pain are mixed, trying to interface to Java via rJava for using Mallet as a topic modelling tool, and when interfacing to Python via reticulate for using Gensim, which is considered the top choice for topic modelling in the Python realm.
The evidence-based approach is to run a benchmark. I want to report results here (including code) that would have bloated the README of the biglda package.
The purpose of the biglda package is to offer functionality and workflows to cope with fitting topic models for large data set sets, i.e. to address performance issues and issues with memory limitations that can be quite a nuisance with biggish data. The package offers an interface to Gensim (Python) and Mallet (Java), but the focus is on Mallet. Considering the results, I believe Mallet is a very good choice for the scenarios I am currently dealing with - fitting various topic models on a corpus with ~ 1 billion words and 2 million documents to evaluate which k is a good choice.
This does not mean that Mallet is my recommendation for any scenario - absolutely not. Please do not skip the discussion at the end of this blog entry! But for know, let me walk you through the benchmarking exercise. Along the way, the code will also acquaint you (superficially) with the biglda package.
The alternatives evaluated in this benchmark are:
- Mallet as exposed to R via biglda
- Gensim as exposed to R via biglda
stm()of the stm R package (structural topic model)LDA(), the classic of the topicmodels R package
As a matter of convenience and reproducibility, we use the AssociatedPress
data included in the topicmodels package, a representation of corpus data as a
DocumentTermMatrix, a class defined in the
tm package. The beauty of this data
format is that every tool considered is able to digest it. We also load the
‘slam’ package for functionality to process the DocumentTermMatrix.
library(slam)
data("AssociatedPress", package = "topicmodels")Admittedly, the Associated Press (AP) data with 2246 documents and 10473 terms is not at all big data. But it is large enough to get a good sense of the performance of different topic modelling tools.
Fitting a model with 100 topics is a good choice for the AssociatedPress
corpus, see the respective evaluation in the vignette of the ldatuning
package.
Here, we just run 100 iterations, which will be enough to assess the performance
of the different implementations of topic modelling. In real life, you would run
more iterations. Mallet and Gensim are multi-threaded and can use multiple
cores. We use all but two cores (on a MacBookPro with 8 cores and an M1 Pro main
processor).
k <- 100L
iterations <- 100L
cores <- parallel::detectCores() - 2LAs we run the tools, we fill a list successively.
benchmarks <- list()We start with Mallet, as exposed to R via biglda.
library(biglda)## Mallet version: v202108## JVM memory allocated: 0.5 Gbinstance_list <- as.instance_list(AssociatedPress, verbose = FALSE)
mallet_started <- Sys.time()
BTM <- BigTopicModel(n_topics = k, alpha_sum = 5.1, beta = 0.1)
BTM$addInstances(instance_list)
BTM$setNumThreads(cores)
BTM$setNumIterations(iterations)
BTM$setTopicDisplay(0L, 0L) # no intermediate report on topics
BTM$logger$setLevel(rJava::J("java.util.logging.Level")$OFF) # remain silent
BTM$estimate()
benchmarks[["mallet"]] <- data.frame(
tool = sprintf("mallet_%d", cores),
time = as.numeric(difftime(Sys.time(), mallet_started, units = "mins"))
)We continue with Gensim, which is run in a virtual Python environment from R using reticulate.
library(reticulate)
gensim <- reticulate::import("gensim")
bow <- dtm_as_bow(AssociatedPress)
dict <- dtm_as_dictionary(AssociatedPress)
gensim_started <- Sys.time()
gensim_model <- gensim$models$ldamulticore$LdaMulticore(
corpus = py$corpus,
id2word = py$dictionary,
num_topics = k,
iterations = iterations,
per_word_topics = FALSE,
workers = cores
)
benchmarks[["gensim"]] <- data.frame(
tool = sprintf("gensim_%d", cores),
time = as.numeric(difftime(Sys.time(), gensim_started, units = "mins"))
)We then want look at the classic implementation of the topicmodels R package.
library(topicmodels)
topicmodels_started <- Sys.time()
lda_model <- LDA(
AssociatedPress,
k = k,
method = "Gibbs",
control = list(iter = iterations)
)
benchmarks[["topicmodels"]] <- data.frame(
tool = "topicmodels",
time = difftime(Sys.time(), topicmodels_started, units = "mins")
)Finally, we look at the structural topic model, the stm package.
library(stm)## stm v1.3.6 successfully loaded. See ?stm for help.
## Papers, resources, and other materials at structuraltopicmodel.comAP <- readCorpus(AssociatedPress, type = "slam")
stm_started <- Sys.time()
stm_model <- stm(
documents = AP$documents,
vocab = AP$vocab,
K = k,
reportevery = 0L,
verbose = FALSE,
max.em.its = iterations,
init.type = "LDA"
)
benchmarks[["stm"]] <- data.frame(
tool = "stm",
time = difftime(Sys.time(), stm_started, units = "mins")
)And this is the result!
library(ggplot2)
ggplot(data = do.call(rbind, benchmarks), aes(x = tool, y = time)) +
geom_bar(stat = "identity")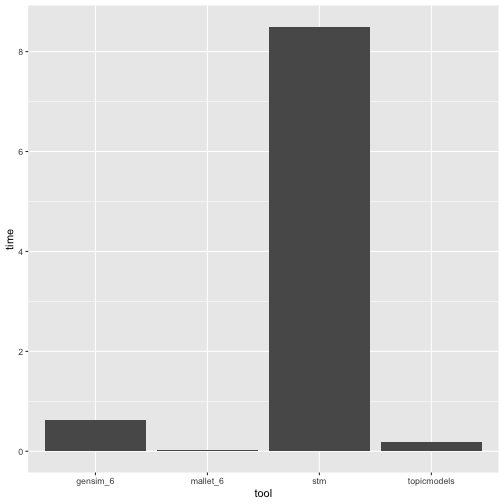
Quite clearly, Mallet is the fastest option. Good news for me! The effort I have
invested in developing the biglda package is not in vain. In fact, there is
another R package simply called mallet that exposes Mallet to R. Unfortunately,
it does not expose the multi-threaded ParallelTopicModel. This is what biglda
does - plus some extra functionality to manage issues of memory limitations and
efficiency at the R-Java-interface. So I am glad to find that biglda speeds up
topic modelling quite a bit.
I am somewhat surprised to see that Gensim is so much slower, and even slower than the topicmodels LDA implementation. I somehow suspect that running Gensim in a virtual environment via reticulate may limit the access of Python to full system resourses. Advice how the performance of Gensim could be improved is welcome! And it is important to note that Gensim may deal with big data exceeding the main memory of a machine (unlike Mallet), and Gensim is able to use distributed computing. So even if Gensim is slower than Mallet, there are big data scenarios with a strong case for Gensim.
The comparatively weak performance of stm is the second surprise for me. But there are many things that stm offers that are absolutely nice and beyond the capabilities of Mallet (Gensim and topicmodels): Rich tools for evaluating topic models and, of course, the capability of the algorithm to process metadata. So stm is the perfect choice for a considerable bandwith of scenarios.
So the message is: For fitting topic models for bulky data, if you need (various) topic models within reasonable time and if memory limitations are an issue, Mallet is a great choice. And biglda is designed for R users to take advantage of the full potential of this topic modelling tool.
Feedback welcome!
Subscribe via RSS