Chapter 7 Annex
7.1 Deutsche Kurzdarstellung
Dieser Artikel stellt das MigParl-Korpus vor. Es werden die verfügbaren Daten, der Datenaufbereitungsprozess zur Erstellung von Plenardebattenkorpora sowie die Samplingstrategie zur Gewinnung eines thematisch kohärenten Korpus von Debatten zum Thema Migration und Integration beschrieben.
7.1.1 Ein Korpus von Plenarprotokollen
MigParl ist ein CWB-indiziertes, linguistisch annotiertes Korpus von Plenarreden in den deutschen Bundesländern, die sich mit Themen der Migration und Integration befassen. Es wurde im Rahmen des MigTex Projektes (Projektleiter: Andreas Blätte / Universität Duisburg-Essen, Ruud Koopmans / Wissenschaftszentrum Berlin) unter Rückgriff auf die Ressourcen und die Infrastruktur des PolMine Projektes entwickelt. MigTex war Teil eines größeren Gemeinschaftsprojektes zur Etablierung der Forschungsgemeinschaft des Deutschen Zentrums für Integrations- und Migrationsforschung (DeZIM). Es wurde vom Bundesministerium für Familie, Senioren, Frauen und Jugend (BMFSFJ) im Rahmen einer Förderung zur Entwicklung der DeZIM-Gemeinschaft gefördert.
Das Korpus knüpft an das GermaParl-Korpus an, ein Korpus von Plenarprotokollen des deutschen Bundestages, das im PolMine-Projekt entwickelt wurde. Als solches folgt es der Motivation und dem allgemeinen Verwendungszweck von GermaParl (siehe Blätte and Blessing 2018: 810). Da die Anwendungsfälle und Anforderungen eines Korpus von Plenarprotokollen in Blätte and Blessing (2018) ausführlich beschrieben sind, liegt hier der Schwerpunkt bei der Beschreibung der spezifischen Merkmale von MigParl.
Das MigParl-Korpus umfasst den Zeitraum von (mehrheitlich) Januar 2000 bis Dezember 2018. Während 14 der 16 Bundesländer Daten für etwa diesen Zeitraum zur Verfügung stellen, liegen für Rheinland-Pfalz (vor Mai 2001) sowie das Saarland (vor September 2004) keine verarbeitbaren Plenarprotokolle für den gesamten Zeitraum vor. Als thematisch spezialisiertes Korpus enthält MigParl nicht alle Debatten, sondern berücksichtigt nur die für die Migrations- und Integrationsforschung relevanten Beiträge. Zur verwendeten Auswahlstrategie gibt Abschnitt “Auswahlstrategie” Auskunft.
MigParl wird als CWB-Korpus in Form eines tar-Archivs über das open-access repository Zenodo zur Verfügung gestellt. Von dort kann es sowohl für den unmittelbaren Gebrauch mit der Corpus Workbench als auch zur Analyse im polmineR-Paket heruntergeladen werden. Im Abschnitt Verwendung des MigParl-Korpus wird im Detail auf die zweite Option eingegangen.
Während der Projektlaufzeit des MigTex-Projektes wurden drei Versionen des Korpus in verschiedenen Zusammenhängen präsentiert, die sich in Hinblick auf Aufbereitungsstand, Datenqualität und inhaltlicher Zusammensetzung unterscheiden. Im Sinne des Nachhaltigkeit und Reproduzierbarkeit werden alle drei Korpusversionen weiterhin verfügbar gehalten. Die nachfolgenden Ausführungen beziehen sich hierbei auf die im Projektkontext finale Fassung (Version 2020.01.27). Für alle Versionen werden Datenberichte sowie die Dokumentation der Datenaufbereitung zur Verfügung gestellt. Für eine Übersicht siehe hier
7.1.2 Korpusaufbereitung
Das Ziel des folgenden Aufbereitungsworkflows ist die Umwandlung von - aus Maschinenperspektive - sparsam strukturierten Textdaten in eine nachhaltige Forschungsressource. Technischer ausgedrückt werden Plenarprotokolle gesammelt (überwiegend pdf-Dokumente) und in TEI-kompatible XML-Dateien umgewandelt. Diese TEI-XML-Dateien können dann mit der Corpus Workbench indexiert werden (Evert and Hardie 2011). Dies ermöglicht die effiziente wissenschaftliche Nutzung auch großer Textkorpora.
Die Erstellung der TEI-Version von MigParl setzt den folgenden Workflow um:
Preprocessing: Erstellung konsoldierter “plain text” (txt) Dokumente in UTF-8-Encoding, mehrheitlich aus PDF-Dateien
XMLification: Umwandlung dieser Textdateien in TEI-Kompatibles XML. Extraktion von Metadaten, Annotation der Sprecher\*innen, etc.
Konsolidierung: Konsolidierung der Sprecher\*innennamen und Anreicherung der Dokumente mit weiteren Informationen aus externen Datenquellen
Für die Erstellung der plain text-Dokumente kam überwiegend das im PolMine-Kontext entwickelte R-Paket trickypdf zum Einsatz. Plenarprotokolle werden fast ausschließlich in zweispaltigen Layouts veröffentlicht, sodass die Entwicklung und der Einsatz dieses Paketes an dieser Stelle Voraussetzung für die Gewinnung sauberer Ausgangsdaten waren. Als Ausnahme bot Hessen für zwei Jahre (bis 2002) Plenarprotokolle ausschließlich in Form von Microsoft Word Dokumenten (.doc) an, die in plain text umgewandelt wurden.
Für die Umwandlung von plain text in strukturell annotiertes, TEI-kompatibles XML (“XMLification”) wurde das beschriebene frappp Paket (framework for parsing plenary protocols) genutzt. frappp ermöglicht einen Workflow, bei dem reguläre Ausdrücke für jene Text- bzw. Sprachmuster im Text definiert werden können, die für ein maschinell lesbares Format mit XML-Elementen ausgezeichnet werden sollen. Dies ist vor allem für Metadaten, Sprecher*innen, Zwischenrufe oder Tagesordnungspunkte der Fall. False positives und False negatives werden durch eine Liste bekannter Fehltreffer sowie einiger Bereinigungsschritte entfernt. Dies bedeutet, dass das Verfahren zwar grundsätzlich vollautomatisiert ist, doch eine erhebliche manuelle Nachkorrektur erforderlich bleibt. Am Ende dieses Prozesses liegen die Plenardebatten in einem maschinenlesbaren Format vor. Diese Daten können in einem folgenden Schritt linguistisch annotiert werden. Die XML/TEI-Version der ursprünglichen Plenarprotokolle wird hierfür durch eine Pipeline von Standardaufgaben des Natural Language Processing (NLP) geführt. Für die Tokenisierung, Part-of-Speech- (POS), sowie Named-Entity- (NE) Annotation wird Stanford CoreNLP verwendet (Manning et al. 2014). Um Lemmata zum Korpus hinzuzufügen, wird TreeTagger (Schmid 1995) verwendet. Weiterführende Informationen zu diesem Prozess werden in der “Technical Documentation” dargestellt.
7.1.3 Auswahlstrategie
MigParl ist eine thematisches Subset von Plenarprotokollen, die für die Migrations- und Integrationsforschung relevant sind. Aus diesem Grund war eine Auswahlstrategie notwendig, um diese Relevanz aus einer Grundgesamtheit aller Protokolle des deutschen Bundeslandes zu ermitteln. Wir verfolgen hier einen zweigleisigen Ansatz.
7.1.3.1 Topic Modelling-Ansatz
- Topic Modelling: Für jeden der Landesparlamentskorpora wurde ein eigenes Topic Model berechnet und die 100 relevantesten Begriffe pro Topic ermittelt. Die Zahl der zu ermittelnden Topcs, die als Hyperparameter in den Algorithmus eingeht, wurde in einem vorgeschalteten Optimierungsverfahren bestimmt
- Themenidentifikation: Eine Reihe von Kernbegriffen, die das Konzept der Migration und Integration vermitteln, wurden durch Literaturrecherche theoretisch abgeleitet. Hierbei wurde das Diktionär von Blätte and Wüst (2017) genutzt und erweitert. Dieses Diktionär und die 100 relevantesten Begriffe pro Topic wurden gegeneinander abgeglichen. Ein Thema mit mehr als fünf Treffern aus dem Wörterbuch wurde als relevant eingestuft
- Dokumentenidentifikation: Für jede Rede wurde die Wahrscheinlichkeit berechnet, zu einem der identifizierten Topics zu gehören. Wenn die summierte Wahrscheinlichkeit einen Schwellenwert überschritt, wurde die Rede als relevant betrachtet
- Die entsprechenden Reden gehen in das MigParl Korpus ein.
7.1.3.2 Diktionärsansatz
- das MigPress-Diktionär (Blätte, Schmitz-Vardar, and Leonhardt 2020) wurde genutzt, um Reden zu identifizieren, in denen mindestens fünf Instanzen dieser Suchterme auftreten.
- dies weicht von dem Schwellenwert von einem Suchterm ab, der für die Erstellung des MigPress-Korpus genutzt wurde. Diese Entscheidung wurde aufgrund des unterschiedlichen Sprachgebrauchs in der parlamentarischen Arena und der größeren durchschnittlichen Länge einer Rede verglichen mit einem durchschnittlichen Zeitungsartikels getroffen
- Die entsprechenden Reden sind ebenfalls in das MigParl Korpus eingegangen.
7.1.4 Annotation
7.1.4.1 Linguistische Annotation
Die oben angesprochene linguistische Annotation ist als sogenannte positionale Attribute (p-Attribute) Teil des Korpus. Die folgende Tabelle gibt kurze Erläuterungen zu den p-Attributen im MigParl-Korpus.
Im sogenannten Tokenstream sieht die linguistische Annotation folgendermaßen aus:
7.1.4.2 Strukturelle Annotation (Metadaten)
Im XML/TEI-Datenformat werden alle Passagen ununterbrochener Sprache mit Metadaten, so genannten strukturellen Attributen (s-Attributen), versehen. Diese Strukturierung bildet auch die Grundlage für die Bildung von Subkorpora. Parlamentarische Reden werden häufig durch Interjektionen unterbrochen - die Information, ob es sich bei einer Äußerung um eine Interjektion oder um eine eigentliche Rede handelt, bleibt im Korpus erhalten. Zu weiteren sturkturellen Attributen gehören u. a. Legislaturperiode, Sitzungsperiode, Datum, Name des Redners / der Rednerin und der dazugehörigen Partei. Die strukturelle Annotation ist die Grundlage für alle Arten von diachronen oder synchronen Vergleichen, die die Benutzer durchführen möchten.
Die folgende Tabelle gibt kurze Erläuterungen zu den s-Attributen, die im MigParl-Korpus vorhanden sind.
7.1.5 Verwendung des MigParl-Korpus
7.1.5.1 Erste Schritte - MigParl installieren
Die CWB indizierte Version von MigParl kann mit dem Corpus Query Processor selbst oder mit jedem Tool, das die CWB als Backend nutzt (wie z.B. CQPweb), verwendet werden. Bei den meisten technischen Entscheidungen während der Korpuserstellung wurde jedoch darauf geachtet, die Verwendung des MigParl-Korpus in Kombination mit dem polmineR-Paket zu optimieren. Bitte konsultieren Sie die Dokumentation des polmineR-Pakets (README, Vignette, Handbuch), um zu erfahren, wie Sie polmineR für die Arbeit mit MigParl nutzen können. Insbesondere die UCSSR-Foliensätze stellen darüber hinaus eine sehr umfassende Lernressource für die Arbeit mit polmineR dar.
Für die Arbeit mit polmineR muss das Korpus zunächst installiert werden. Hierfür steht mit cwbtools ein Paket aus dem PolMine-Kontext bereit, das die einfache Installation von Korpora ermöglicht, die auf Zenodo hinterlegt sind. Vorausgesetzt ist cwbtools mindestens in der Version 0.2.0.9004, die gegenwärtig wie folgt von GitHub installiert werden muss.
if (!"devtools" %in% installed.packages()[,"Package"]) install.packages("devtools")
devtools::install_github("PolMine/cwbtools", ref = "dev")Wie eingangs beschrieben, werden verschiedene Versionen des Korpus auf Zenodo angeboten. Im englischsprachigen Hauptteil des Dokumentes sowie in dieser deutschsprachigen Übersicht wird die finale Version (2020.01.27) vorgestellt. Die anderen Korpusversionen folgen im weiteren Verlauf des Anhanges. Um die im Projektkontext finale Version des Korpus zu verwenden, muss bei der Installation der korrekte digital object identifier (doi) dieser Version angegeben werden.
Um zu überprüfen, ob die Installation erfolgreich war, führen Sie die folgenden Befehle aus. Weitere Anweisungen finden Sie in der Dokumentation des Pakets polmineR.
7.1.5.2 Ein sehr kurzes Tutorial
An dieser Stelle können wir nur eine sehr kurze Anleitung für die grundlegenden Befehle anbieten. Zuerst möchten Sie sich vielleicht über einige s-Attribute (strukturelle Attribute) und die p-Attribute (positionale Attribute) informieren, die verfügbar sind.
## [1] "speaker" "party" "role" "lp" "session" "date"## [1] "word" "pos" "lemma" "ner"Um etwas über die Ausprägungen von s-Attributen zu erfahren, geben Sie den Parameter s_attribute an:
Um Schlagwörter und ihre Wortumfelder auszugeben, verwenden Sie die kwic()-Methode (Keywords-in-Context):
Die Zählung erfolgt mittels der count()-Methode. Sie können eine oder mehrere Suchanfragen angeben:
## query count freq
## 1: Integration 27166 0.0005277954## query count freq
## 1: Integration 27166 5.277954e-04
## 2: Flucht 2514 4.884332e-05
## 3: Abschiebung 4799 9.323750e-05Um die Streuung einer Abfrage zu erhalten, verwenden Sie die dispersion()-Methode.
Visualisieren des Ergebnisses als Balkendiagramm:
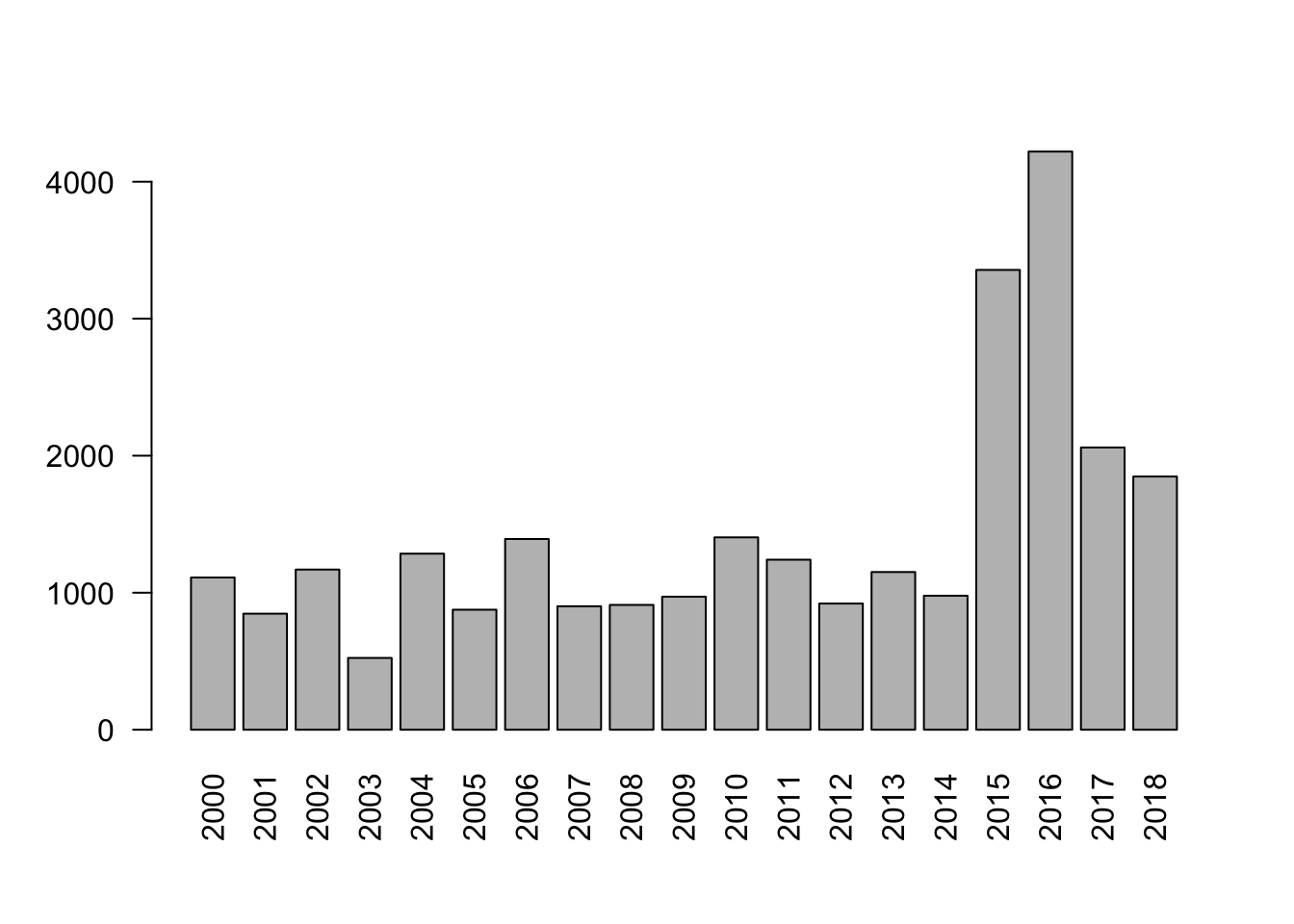
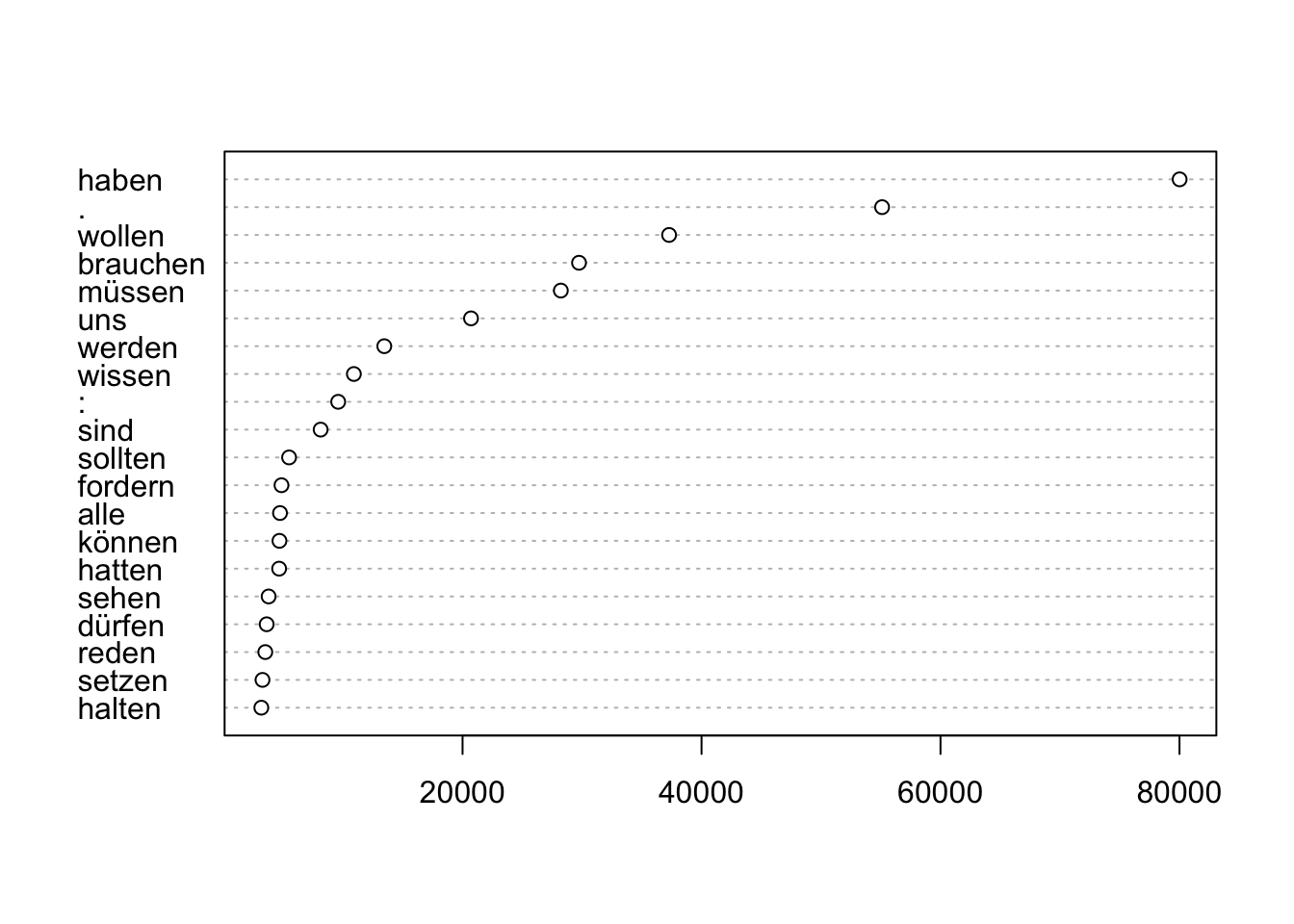
Die coccurrences()-Methode liefert Ihnen Wörter, die zusammen mit dem Suchbegriff öfter vorkommen als statistisch erwartet.
## word ll rank_ll
## 1: haben 80012.91 1
## 2: . 55111.11 2
## 3: wollen 37284.81 3
## 4: brauchen 29747.91 4
## 5: müssen 28225.24 5Diese lassen sich auch einfach visualisieren:
Dies sind einige der Kernfunktionen, die auf den gesamten Korpus angewendet werden. Der wesentliche Punkt der strukturellen Annotation des Korpus (s-Attribute) ist es, die Erstellung von Subkorpora / Partitionen zu erleichtern. So kann jede Methode, die eingeführt wurde, auf eine Partition angewendet werden.
year2016 <- partition("MIGPARL", year = 2016)
count(year2016, query = c("Asyl", "Flucht", "Abschiebung"))## query match count freq
## 1: Asyl Asyl 542 1.038025e-04
## 2: Flucht Flucht 291 5.573159e-05
## 3: Abschiebung Abschiebung 506 9.690785e-05Schließlich ist zu beachten, dass die Methoden von polmineR auch mit der vom magrittr-Paket angebotenen Pipe-Funktionalität verwendet werden können.
cooccurrences("MIGPARL", query = "Europa") %>%
subset(!word %in% c(tm::stopwords("de"), ",", ".")) %>%
subset(count_coi >= 3) %>%
dotplot()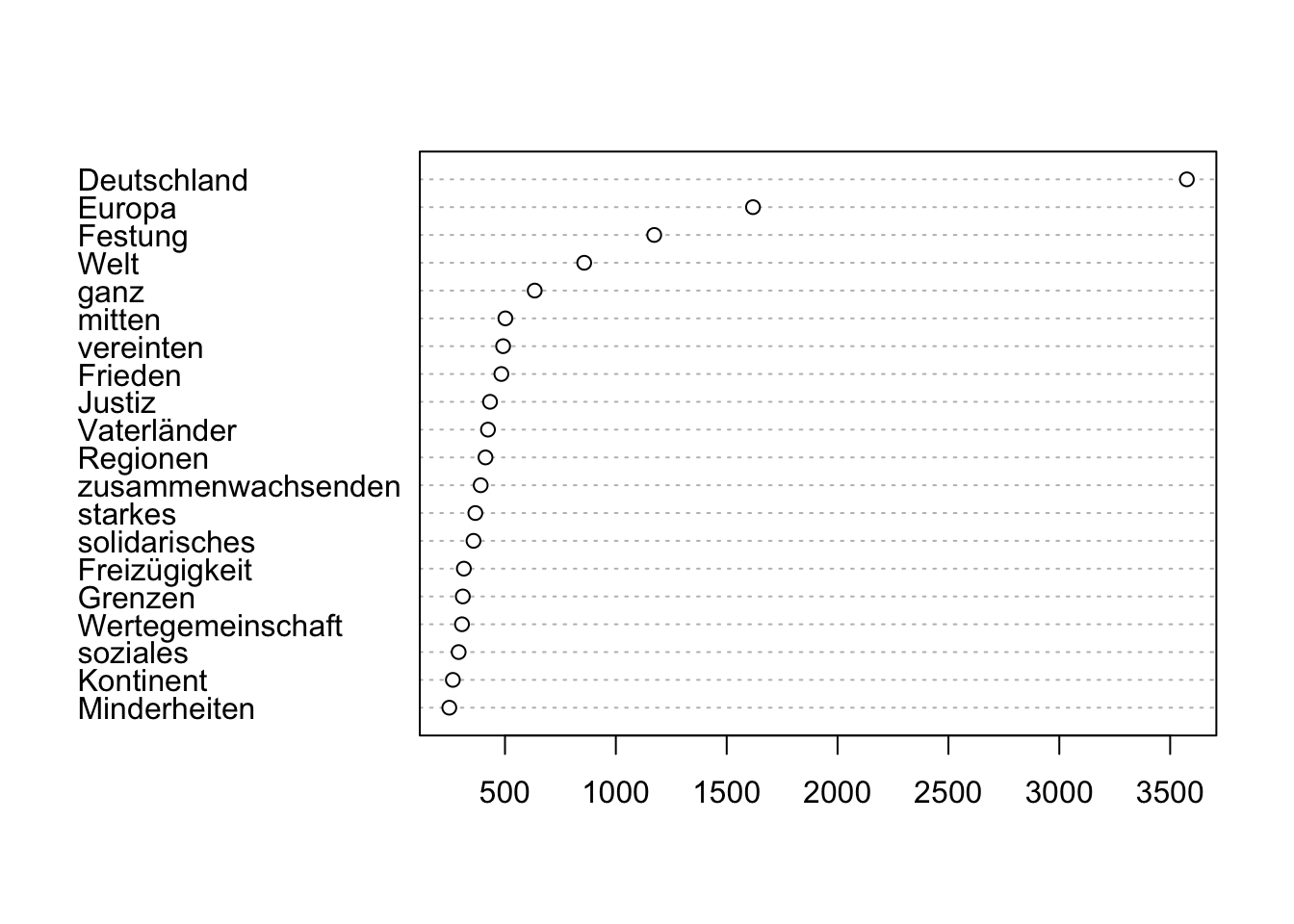
Dies ist nur ein kurzer Einblick in die analytischen Möglichkeiten der Verwendung von MigParl in Kombination mit polmineR. Einer der wichtigsten Aspekte, der hier nicht erläutert werden kann, ist die Möglichkeit, die Syntax des Corpus Query Processors (CQP) zu verwenden, die im CWB-Backend integriert ist. Die as.TermDocumentMatrix()-Methode kann Datenstrukturen effizient aufbereiten, die für weitergehende analytische Techniken wie z.B. Topic Modelling benötigt werden. Bitte lesen Sie die Vignette des polmineR Pakets, um mehr zu erfahren!
7.1.6 Einige Hinweise
Eine Reihe von allgemeinen Anmerkungen soll dabei helfen, mögliche Fallstricke bei der Arbeit mit MigParl zu vermeiden:
Die Plenarprotokolle berichten akribisch über Zwischenrufe. Um die Integrität der Originaldokumente zu erhalten, werden die Einsprüche im Korpus kommentiert. Durch die Verwendung des s-Attributs ‘interjection’, das die Werte ‘TRUE’ oder ‘FALSE’ annimmt, können Sie Ihre Analyse auf Sprache oder Interjektionen beschränken.
Anders als bei GermaParl ist eine Unterscheidung zwischen Parteizugehörigkeit und Fraktion in der aktuellen Version von MigParl nicht enthalten. Dies hat hauptsächlich den praktischen Grund, dass es auf regionaler Ebene nicht allzu viele Unterschiede zwischen Partei und Fraktion gibt, da es keine “CDU/CSU”-Fraktion wie im Deutschen Bundestag gibt.
Für Nutzer*innen, die bereits mit früheren Versionen des
MigParlKorpus gearbeitet haben, ist es unter Gesichtspunkten der Vergleichbarkeit unter Umständen notwendig, ein Subset zu erstellen, das lediglich die Reden berücksichtigt, die mit dem Topic Modelling-Ansatz gesampelt wurden (source_dict == FALSE). In jedem Fall stehen die früheren Versionen von MigParl nach wie vor zur Verfügung und können über den oben dargestellten Mechanismus heruntergeladen werden (hierzu muss lediglich die DOI-Nummer geändert werden).
7.1.7 Fazit
MigParl wird als thematisch fokussiertes Subset der Debatten in den deutschen Landtagen als sprachlich annotierte und indizierte Version zur Verfügung gestellt. Die Datensammlung, die sich über 18 Jahre deutscher Parlamentsdebatten erstreckt, ist vollständig, eine Erweiterung kann in weiteren Projektkontexten erfolgen. Wie bei GermaParl sollen „die Daten offen, versioniert, reproduzierbar, zugänglich und nachhaltig sein, wobei der Schwerpunkt auf der sukzessiven Verbesserung der Datenqualität liegt" (Blätte and Blessing 2018: 816). Da MigParl an den Bestrebungen von GermaParl anknüpft, indem es die Arbeitsabläufe, Ressourcen und methodischen Überlegungen zusammen mit den Daten öffentlich zugänglich macht, wird angestrebt, dass die Daten zur Förderung eines öffentlichen, digitalen Archivs der Demokratie beitragen können.
7.1.8 Lizenz
Während die Rohdaten (die von den Bundesländern veröffentlichten Plenarprotokolle) öffentlich zugänglich sind, wird das MigParl-Korpus mit einer CC BY+SA-Lizenz bereitgestellt. Das bedeutet:
BY - Namensnennung - Sie müssen angemessene Urheber- und Rechteangaben machen, einen Link zur Lizenz beifügen und angeben, ob Änderungen vorgenommen wurden. Diese Angaben dürfen in jeder angemessenen Art und Weise gemacht werden, allerdings nicht so, dass der Eindruck entsteht, der Lizenzgeber unterstütze gerade Sie oder Ihre Nutzung besonders.
SA - Weitergabe unter gleichen Bedingungen — Wenn Sie das Material remixen, verändern oder anderweitig direkt darauf aufbauen, dürfen Sie Ihre Beiträge nur unter derselben Lizenz wie das Original verbreiten.
Diese und weitere Erklärungen finden Sie in der CC Attribution-ShareAlike 4.0 Unported Lizenz.
7.1.9 Zitation
Wenn Sie mit dem MigParl-Paket arbeiten, fügen Sie bitte die der verwendeten Korpusversion entsprechenden Referenz in Ihre Bibliographie ein, um die Sprachressource zu referenzieren. Die genaue Zitation kann auf Zenodo eingesehen werden.
7.2 Corpus Version 2018.11.27
7.2.1 Data Report
## This is a data report for the MIGPARL2018 corpus (corpus version: 2018.11.27)7.2.1.1 Corpus Size
The size of the entire corpus is about 27.24 million tokens.
7.2.1.2 Positional Attributes
The following positional attributes are available:
## - word
## - pos
## - lemma7.2.1.3 Structural Attributes
The following structural attributes are available:
## - id
## - speaker
## - party
## - role
## - lp
## - session
## - date
## - regional_state
## - interjection
## - year
## - agenda_item
## - agenda_item_type
## - speech
## - topics
## - harmonized_topics7.2.1.3.1 Structural Attribute “date” (and year)
The corpus covers the time span between 1994-10-20 and 2018-05-31. There are 0 missing values in the date attributes.
7.2.1.3.2 Size per Date
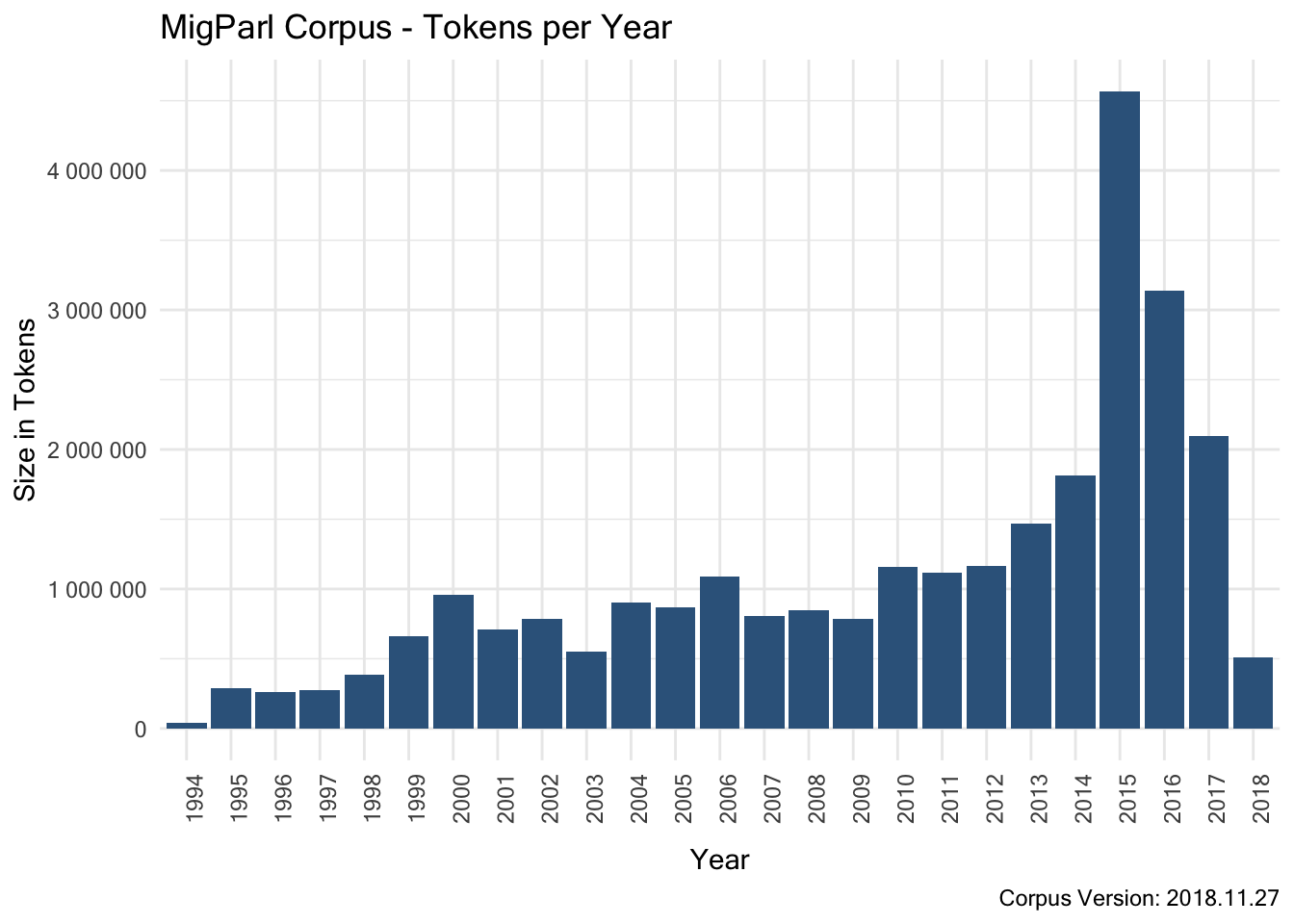
7.2.1.3.3 Size per Year
7.2.1.3.4 Structural Attribute “party”
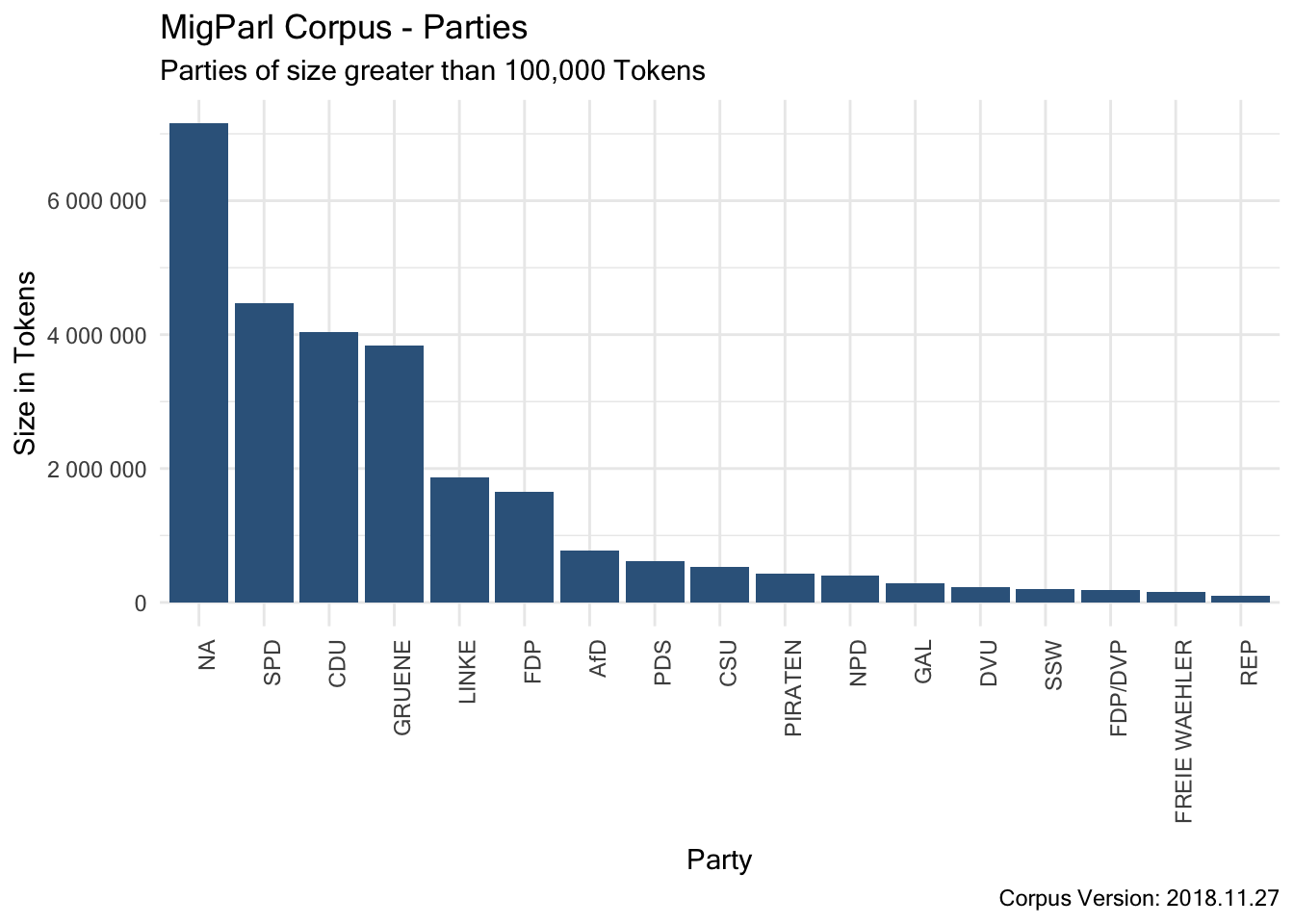
7.2.1.3.5 Structural Attribute “role”
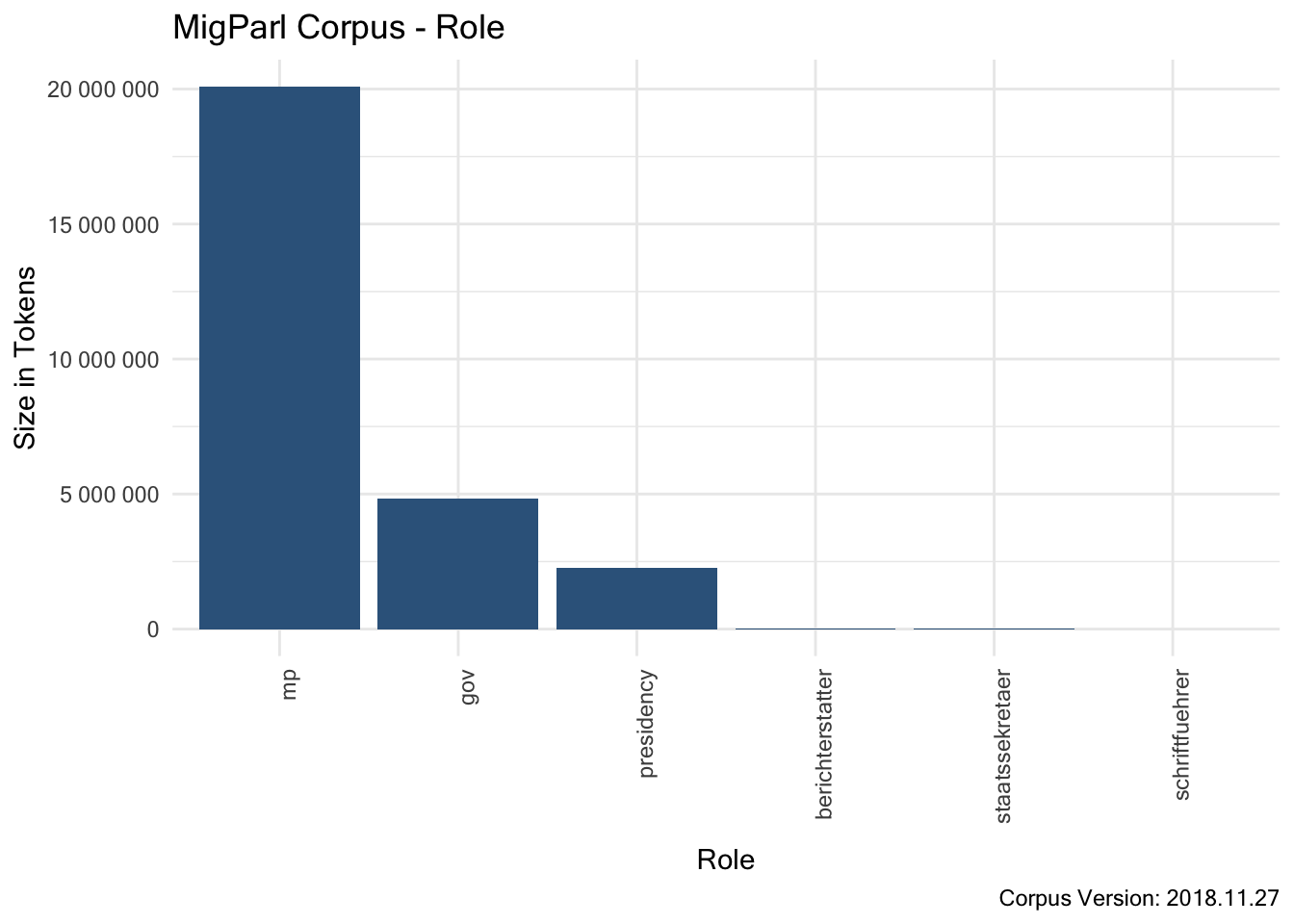
7.2.1.3.6 Structural Attribute “speaker”
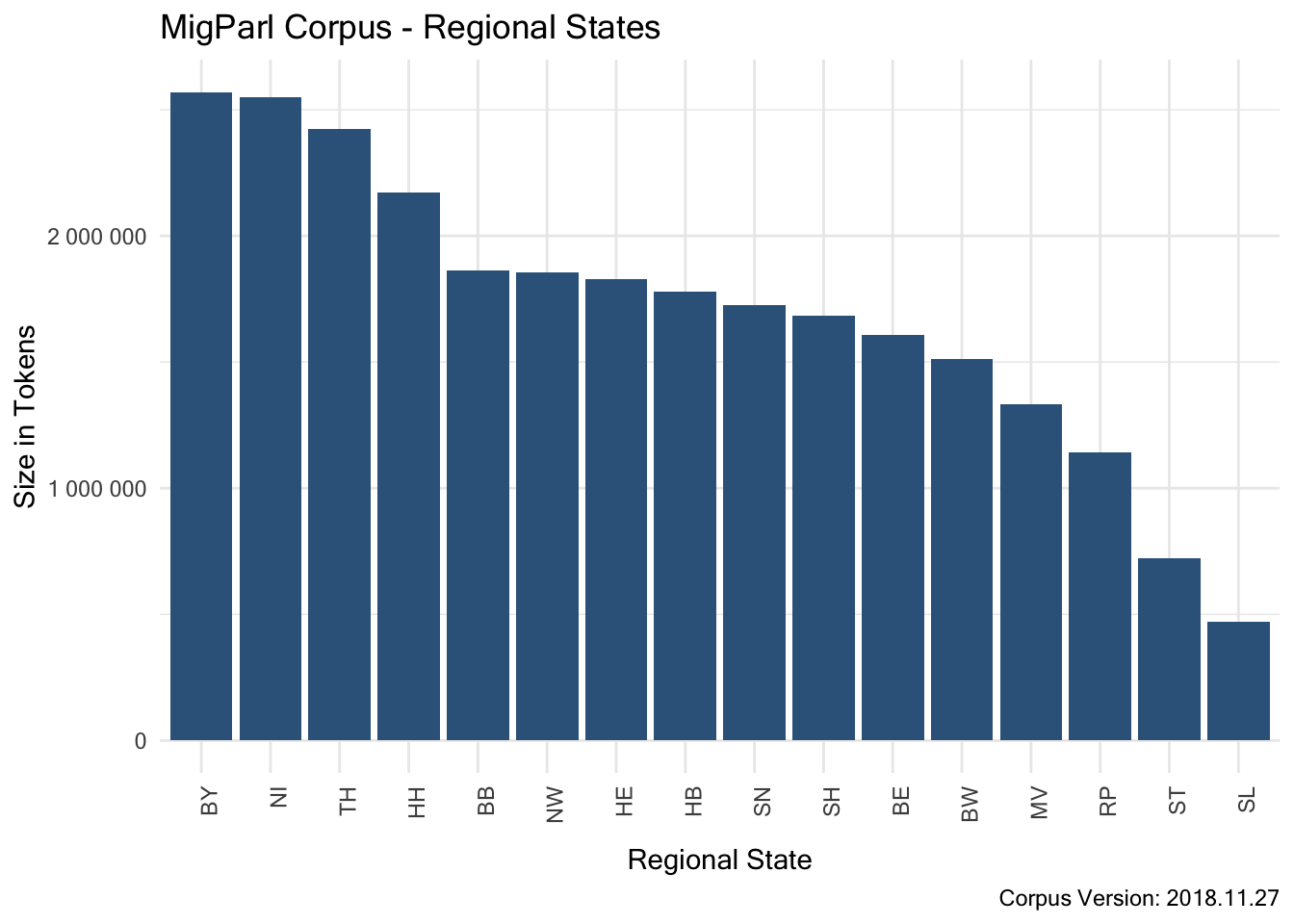
7.2.1.3.7 Structural Attribute “regional_state”
7.2.2 Technical Documentation
The MigParl corpus (Version 2018.11.27) is based on indexed and linguistically annotated corpora of parliamentary protocols of the German federal states (Bundesländer) (Corpus Build Date: 2018-10). As decribed under corpus preparation, the raw protocols have been processed using a pipeline of different R packages to create TEI/XML. Stanford CoreNLP (Manning et al. 2014) (for tokenization and part-of-speech tagging) and TreeTagger (Schmid 1995) (for lemmatization) were used for linguistic annotation. Named Entity recognition was only implemented in the subsequent versions of the corpus. The data was imported into the Corpus Workbench (Evert and Hardie 2011) which facilitates the management of large text corpora.
Based on these initial corpora, the following section describes the selection strategy, i.e. which parts of the corpora have been regarded as relevant for migration and integration research.
7.2.2.1 Report
7.2.2.2 Topic Modelling Remarks
The following table provides an overview about the selected topics as returned by the topic modelling process (fitted with k = 250) and qualitatively identified by the MigTex team.
7.3 Corpus Version 2019.11.03
7.3.1 Data Report
## This is a data report for the MIGPARL2019 corpus (corpus version: 2019.11.03)7.3.1.1 Corpus Size
The size of the entire corpus is about 38.69 million tokens.
7.3.1.2 Positional Attributes
The following positional attributes are available:
## - word
## - pos
## - lemma
## - ner7.3.1.3 Structural Attributes
The following structural attributes are available:
## - id
## - speaker
## - party
## - role
## - lp
## - session
## - date
## - url
## - src
## - regional_state
## - interjection
## - year
## - agenda_item
## - agenda_item_type
## - speech
## - migration_integration_probability7.3.1.3.1 Structural Attribute “date” (and year)
The corpus covers the time span between 2000-01-19 and 2018-12-20. There are 0 missing values in the date attributes.
7.3.1.3.2 Size per Date
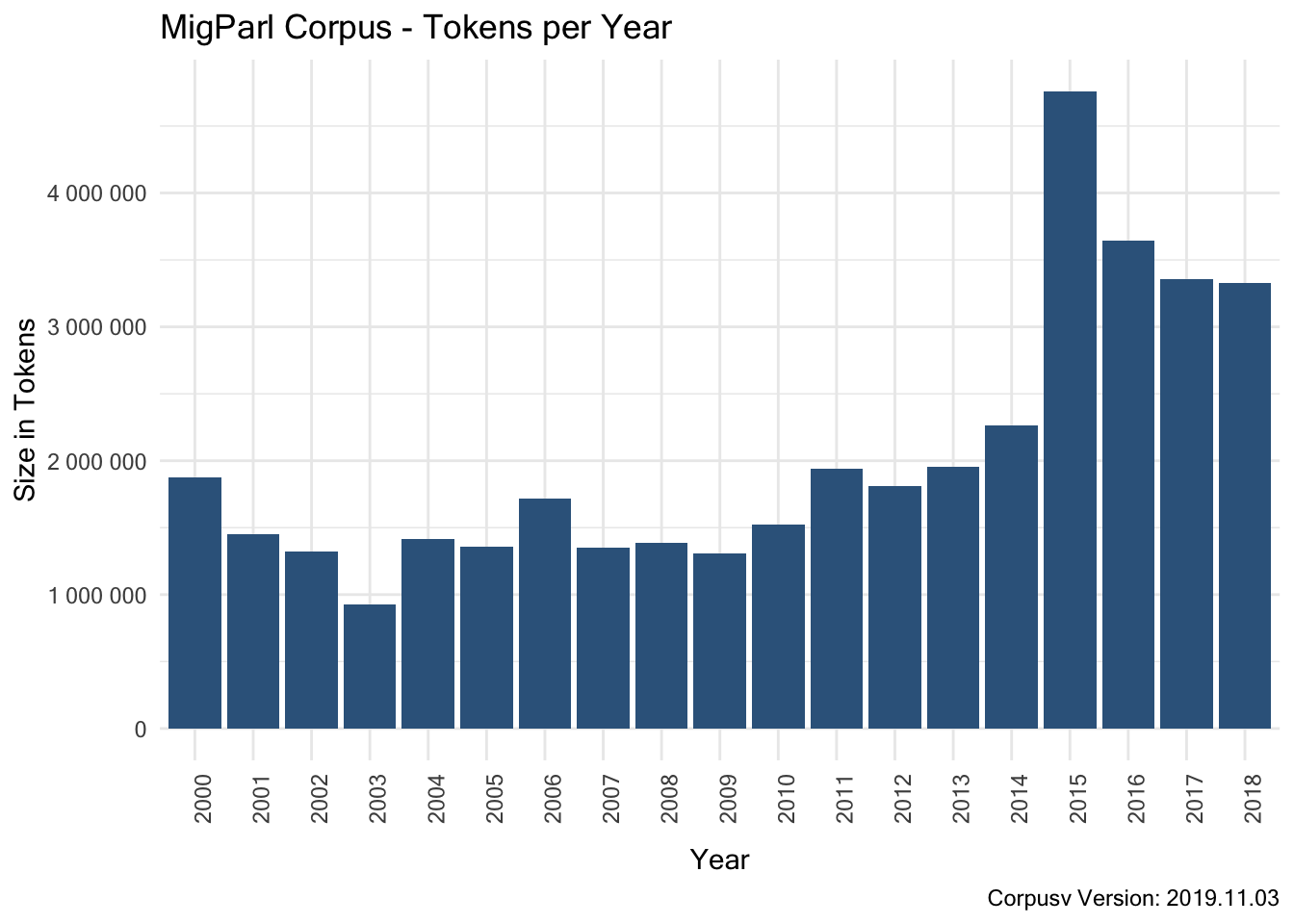
7.3.1.3.3 Size per Year
7.3.1.3.4 Structural Attribute “party”
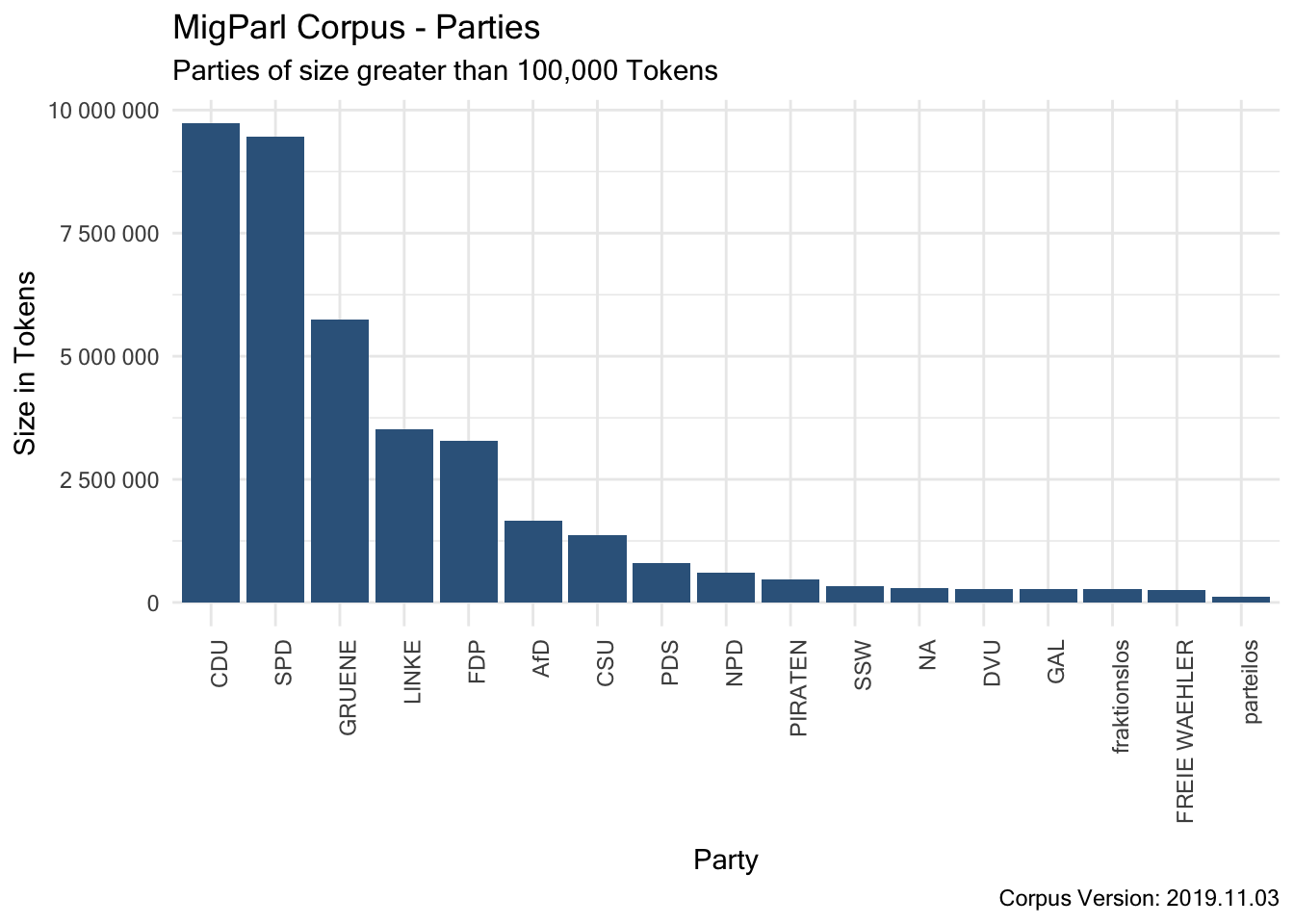
7.3.1.3.5 Structural Attribute “role”
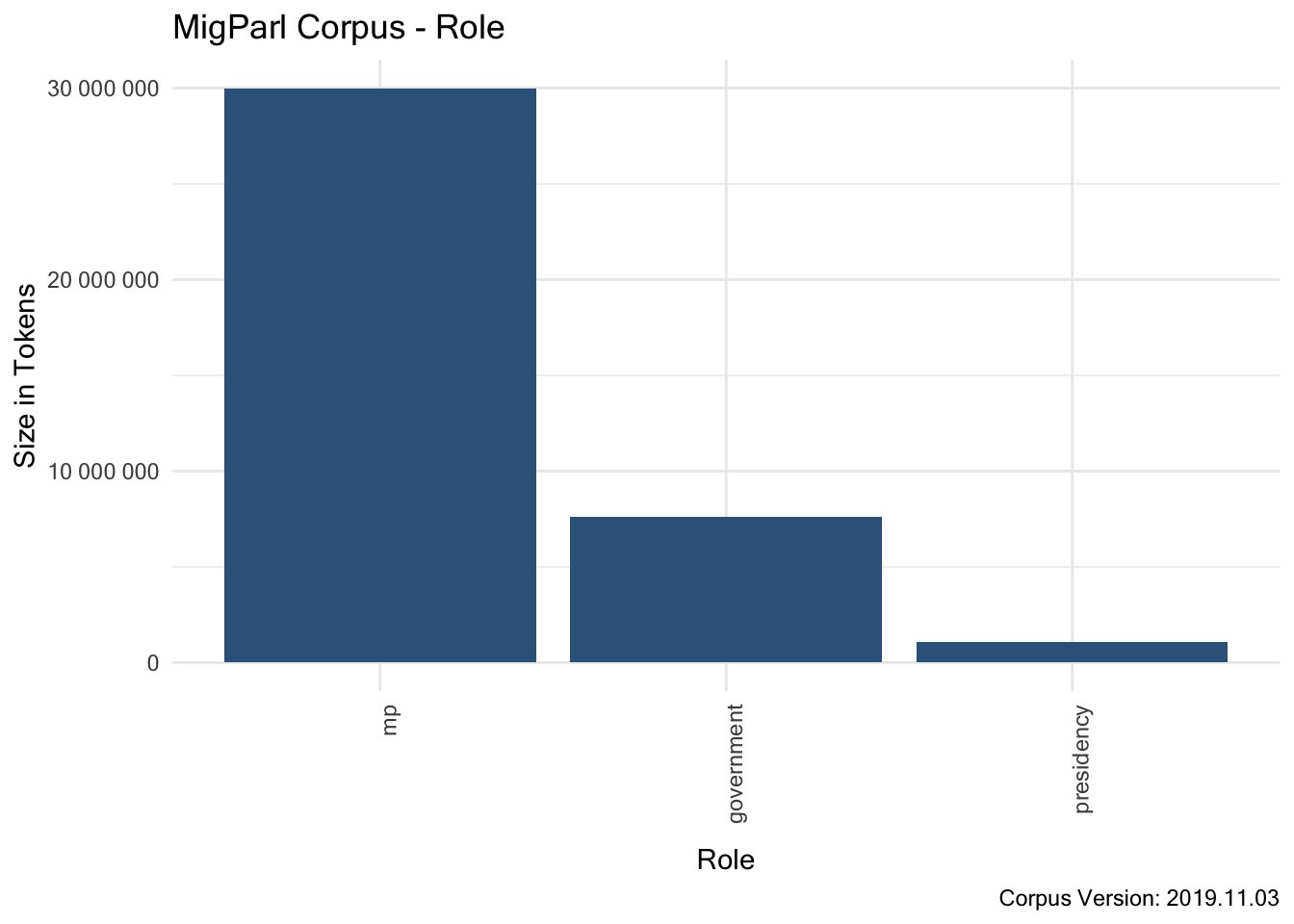
7.3.1.3.6 Structural Attribute “speaker”
7.3.1.3.7 Structural Attribute “regional_state”
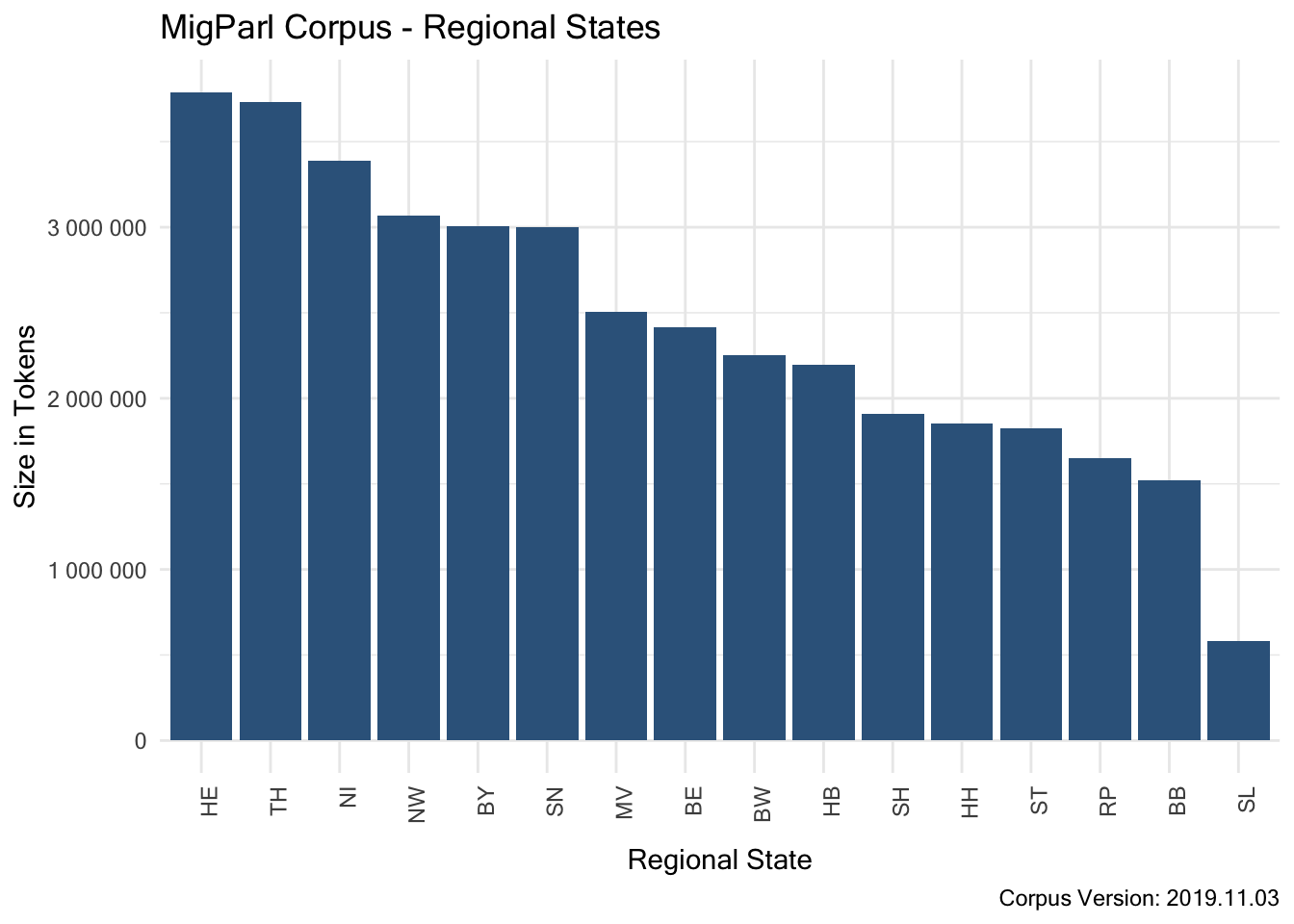
7.3.2 Technical Report
The MigParl corpus (Version 2019.11.03) is based on indexed and linguistically annotated corpora of parliamentary protocols of the German federal states (Bundesländer) (Corpus Build Date: 2019-10-31). As decribed under corpus preparation, the raw protocols have been processed using a pipeline of different R packages to create TEI/XML. Stanford CoreNLP (Manning et al. 2014) (for tokenization, part-of-speech tagging and named entity recognition) and TreeTagger (Schmid 1995) (for lemmatization) were used for linguistic annotation. The data was imported into the Corpus Workbench (Evert and Hardie 2011) which facilitates the management of large text corpora.
Based on these initial corpora, the following section describes the selection strategy, i.e. which parts of the corpora have been regarded as relevant for migration and integration research.
References
Blätte, Andreas, and Andre Blessing. 2018. “The Germaparl Corpus of Parliamentary Protocols.” In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (Lrec 2018), edited by (Conference chair)Nicoletta Calzolari, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Koiti Hasida, Hitoshi Isahara, et al. Miyazaki, Japan: European Language Resources Association (ELRA).
Blätte, Andreas, Merve Schmitz-Vardar, and Christoph Leonhardt. 2020. “MigPress. A Corpus of Migration and Integration Related Newspaper Coverage.” https://polmine.github.io/MigPress.
Blätte, Andreas, and Andreas M. Wüst. 2017. “Der Migrationsspezifische Einfluss Auf Parlamentarisches Handeln: Ein Hypothesentest Auf Der Grundlage von Redebeiträgen Der Abgeordneten Des Deutschen Bundestags 1996–2013.” PVS Politische Vierteljahresschrift 58 (2): 205–33. https://doi.org/10.5771/0032-3470-2017-2-205.
Evert, Stefan, and Andrew Hardie. 2011. “Twenty-First Century Corpus Workbench: Updating a Query Architecture for the New Millennium.” In.
Manning, Christopher D., Mihai Surdeanu, John Bauer, Jenny Finkel, Steven J. Bethard, and David McClosky. 2014. “The Stanford CoreNLP Natural Language Processing Toolkit.” In Association for Computational Linguistics (Acl) System Demonstrations, 55–60. http://www.aclweb.org/anthology/P/P14/P14-5010.
Schmid, Helmut. 1995. “Improvements in Part-of-Speech Tagging with an Application to German.” In Proceedings of the Acl Sigdat-Workshop. Dublin, Ireland.