Chapter 4 Using MigParl
4.1 Getting started - Installing MigParl
The CWB indexed version of MigParl can be used with the Corpus Query Processor itself, or with any tool that uses the CWB as a back end (such as CQPweb). However, most technical decisions during corpus preparation had in mind to optimise using the MigParl corpus in combination with the polmineR package. Please consult the documentation of the polmineR package (README, Vignette, Manual) to learn how to use polmineR for working with MigParl. The UCSSR-Slides in particular are a useful learning resource when using polmineR.
In general, the polmineR package can be installed like this:
To get the most recent features, the development version of the package can be installed from GitHub. In comparison with the version above, the development version introduces new features, however it might introduce new minor bugs as well as it is not yet consolidated. Making it available on the social coding plattform GitHub does provide community feedback as well.
Working with polmineR, the corpus has to be installed first. For this purpose, cwbtools, an R package of the PolMine family, facilitates an easy workflow to download and install corpora which are stored on Zenodo. The prerequisite is that cwbtools is installed at least in version 0.2.0.9004 which currently has to be installed from GitHub.
As described earlier in the documentation, multiple versions of the corpus are available on Zenodo. In the following description, the final version of the corpus is used. The relevant digital object identifier (doi) must be indicated here.
To check whether the installation has been successful, run the following commands. For further instructions, see the documentation of the polmineR package or the introductory tutorial in the next section.
4.2 A very brief Tutorial
First, you may want to learn about sone of the s-attributes (structural attributes), and the p-attributes (positional attributes) that are available.
## [1] "speaker" "party" "role" "lp" "session" "date"## [1] "word" "pos" "lemma" "ner"To learn about the values of s-attributes, specify the parameter s_attribute:
To inspect keywords-in-context (KWIC), use the kwic()-method:
The count()-method is used for counting. You can supply one or multiple queries:
## query count freq
## 1: Integration 27166 0.0005277954## query count freq
## 1: Integration 27166 5.277954e-04
## 2: Flucht 2514 4.884332e-05
## 3: Abschiebung 4799 9.323750e-05To get the dispersion of a query, use the dispersion()-method.
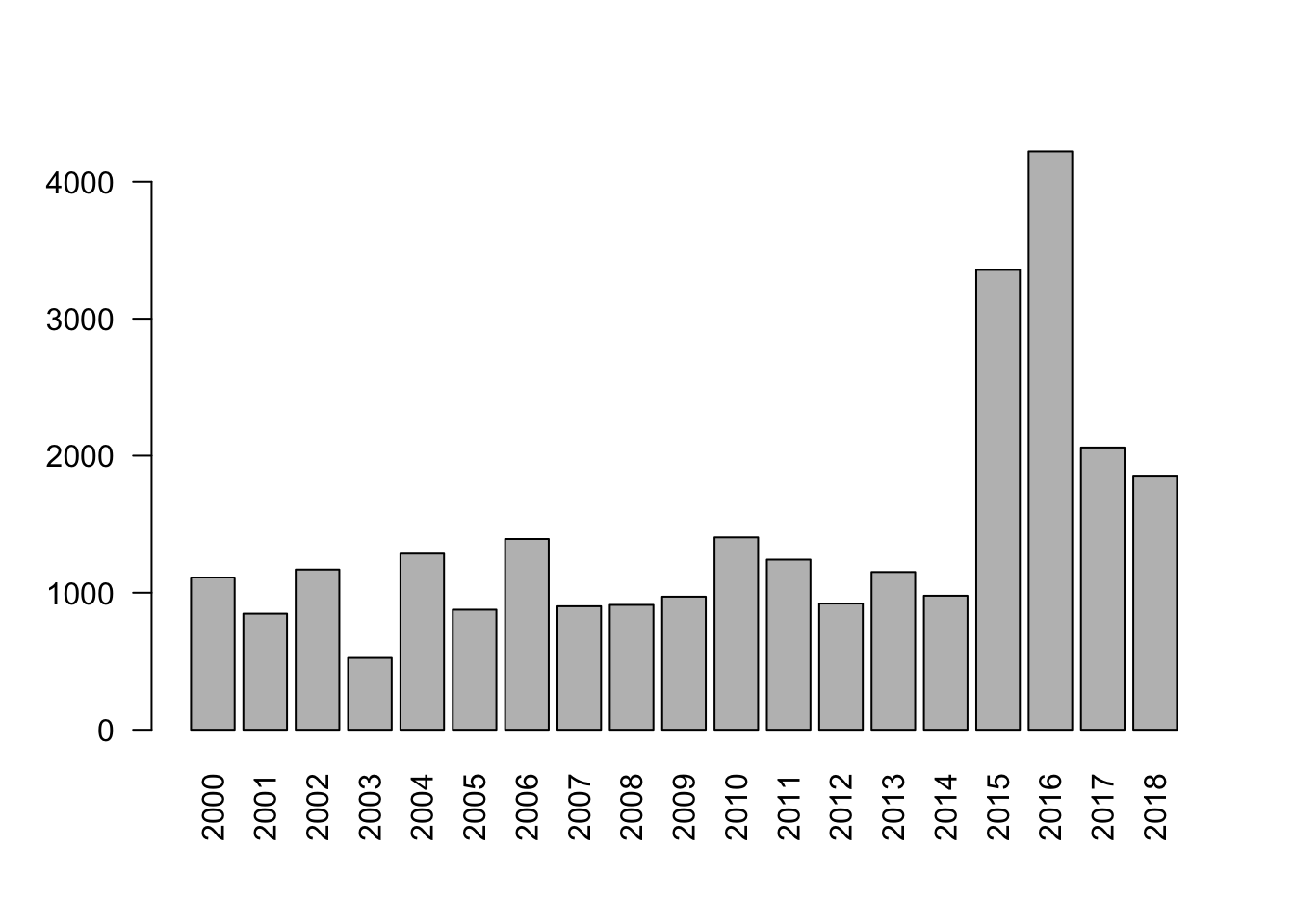
Visualise the result as a barplot:
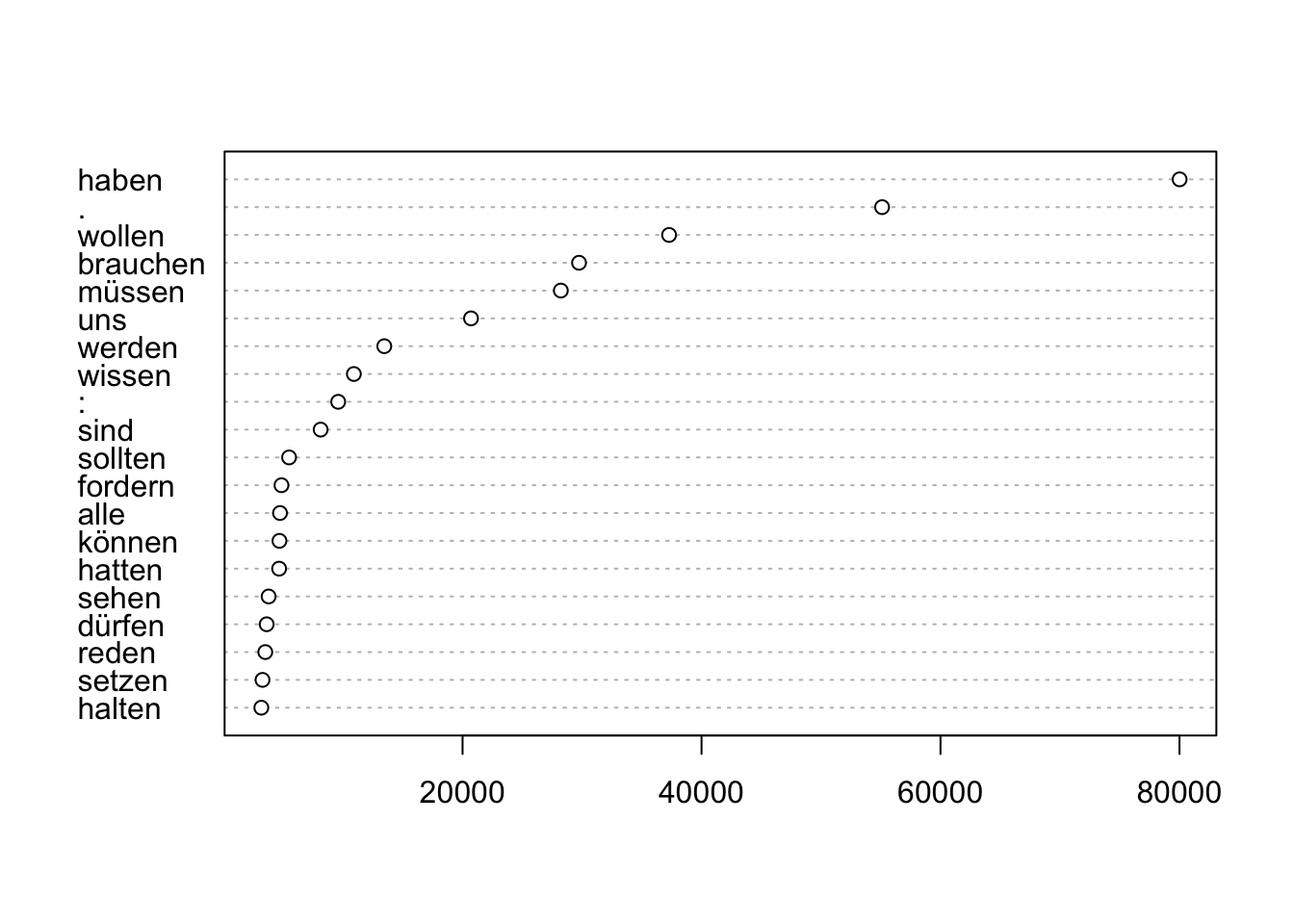
The cooccurrences()-method will get you words which do occur more frequently together with the query term than statistically expected.
## word ll rank_ll
## 1: haben 80012.91 1
## 2: . 55111.11 2
## 3: wollen 37284.81 3
## 4: brauchen 29747.91 4
## 5: müssen 28225.24 5This can be visualized easily.
These are some of the core functions, applied to the entire corpus. The whole point of the structural annotation of the corpus (s-attributes) is to facilitate the creation of subcorpora / partitions. So every method that has been introduced can be applied to a partition.
year2016 <- partition("MIGPARL", year = 2016)
count(year2016, query = c("Asyl", "Flucht", "Abschiebung"))## query match count freq
## 1: Asyl Asyl 542 1.038025e-04
## 2: Flucht Flucht 291 5.573159e-05
## 3: Abschiebung Abschiebung 506 9.690785e-05Finally, note that the methods of polmineR can also be used with the pipe functionality offered by the magrittr package.
cooccurrences("MIGPARL", query = "Europa") %>%
subset(!word %in% c(tm::stopwords("de"), ",", ".")) %>%
subset(count_coi >= 3) %>%
dotplot()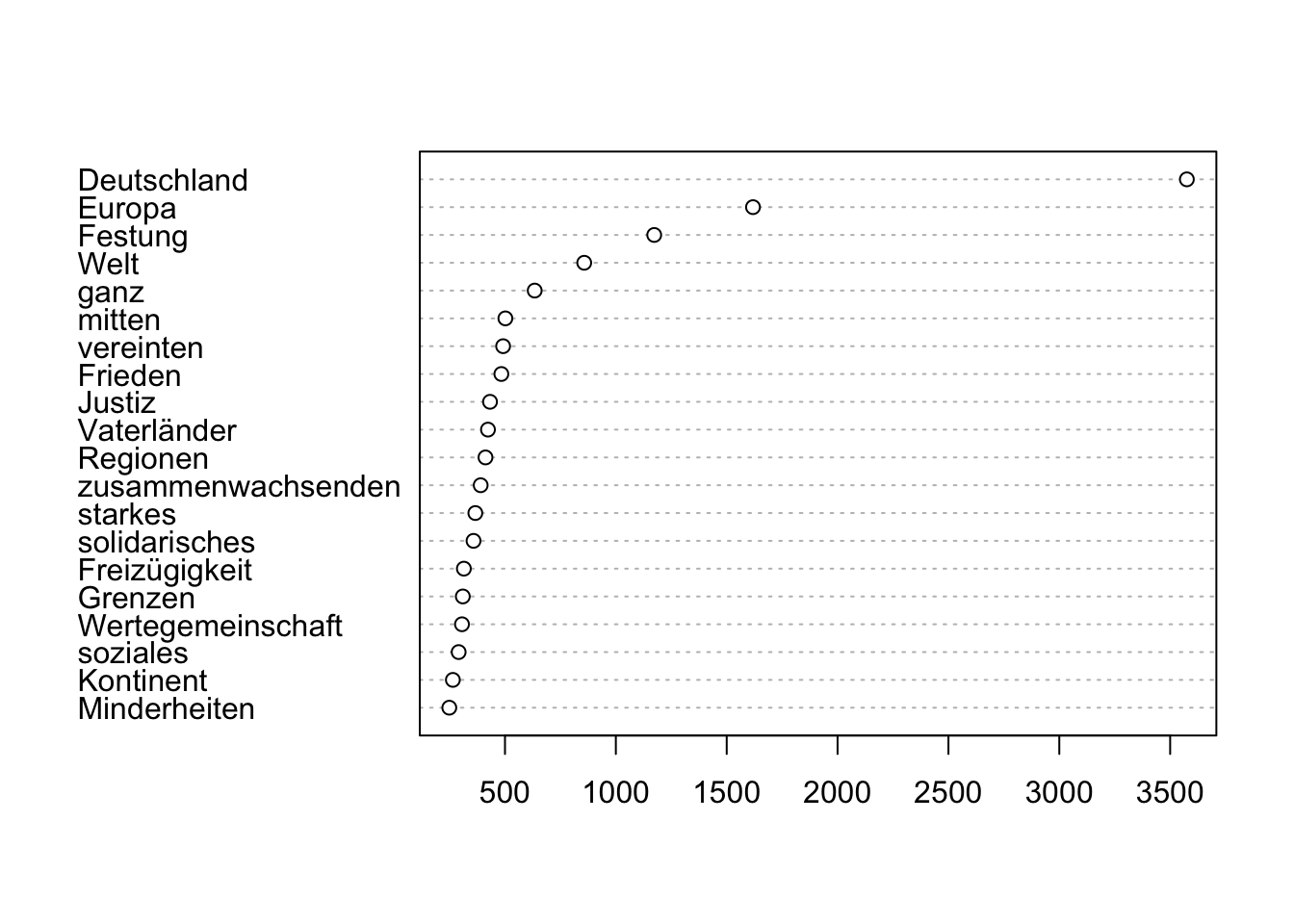
This is just a short glimpse into the analytical opportunities of using MigParl in combination with polmineR. One of the most important aspects that cannot be explained here is the possibility to use the syntax of the Corpus Query Processor (CQP) that comes with the CWB back-end. The as.TermDocumentMatrix() method will prepare data structures efficiently needed for more advanced analytical techniques such as topic modelling. Consult the vignette of the polmineR package to learn more!
4.3 Some caveats
A set of general remarks may help to avoid pitfalls when working with MigParl:
- Plenary protocols meticulously report interjections. To maintain the integrity of the original documents, interjections are annotated in the corpus. By using the s-attribute ‘interjection’ that assumes the values ‘TRUE’ or ‘FALSE’, you can limit your analysis to speech or interjections.
- In contrast to GermaParl, a distinction between party affiliation and parliamentary group is not included in the current version of MigParl. This has mainly the practical reason that there are not too many differences between party and parliamentary group on regional level as there is no “CDU/CSU” parliamentary group as in the German Bundestag.
- For users working with previous versions of
MigParlit might be necessary to subset the corpus so that it only comprises speeches which are sampled with the topic modelling approach (source_dict == FALSE). However as stated, older versions of the corpus can still be downloaded with the mechanism presented earlier.