by Andreas Blätte, Christoph Leonhardt
GermaParl2 Constitution Day Release 2023
We are pleased to announce the public release of GermaParl v2.0.0 corpus today, on Germany’s Constitution Day (May 23, 2023). With GermaParl2, all parliamentary debates of the German Bundestag from 1949 to 2021 become available in a comprehensively annotated format. The public release follows a process of two beta releases in which registered beta users provided valuable feedback on data quality and usability. In taking up these suggestions, we are confident that we are now able to offer a high-quality corpus. This is where the corpus is now available without the need to register. It is available under a Creative Commons license (CC BY-SA 4.0):
-
The data can be downloaded persistently from Zenodo. Available data formats are XML, and an linguistically annotated and indexed version (Corpus Workbench / CWB): https://zenodo.org/record/7949074
-
The XML version of GermaParl2 is also available at GitHub: https://github.com/PolMine/GermaParlTEI
GermaParl2 has been prepared as high-quality data for trustworthy scientific publications. As a matter of transparency, we offer extensive documentation. It includes a presentation of the data, its preparation workflow, and some more technical details as well as acknowledgements and remarks to future work. The documentation of the corpus is available here: https://polmine.github.io/GermaParl2/
GermaParl2 covers the entire post-war history of German parliamentarism up the end of the 19th legislative period. It includes a total of 273550607 tokens. To offer a first glimpse into the data, we may learn from this barplot that the long-term trend is that more and more words are spoken in parliament per legislative period:
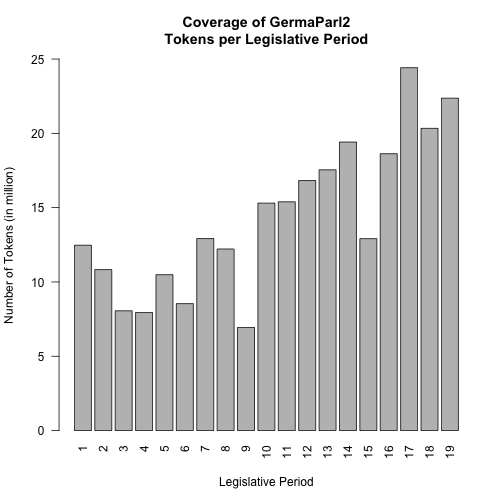
Aside from coverage, comprehensive annotation is a unique feature of GermaParl2. The structure of the data facilitates the segmentation of debates into single utterances enriched with additional metadata. See the following table on the structural annotation of GermaParl2 and how it differs from GermaParl v1.0.6.
| GermaParl v1.0.6 | GermaParl v2.0.0-beta3 | Description |
|---|---|---|
| - | protocol | the main document node attributes |
| lp | protocol_lp | legislative period |
| session | protocol_no | session number |
| date | protocol_date | date in YYYY-MM-DD |
| year | protocol_year | year in YYYY |
| url | protocol_url | the url of the source document |
| src | protocol_filetype | the type of the source document |
| - | speaker | the main speaker node attributes |
| - | speaker_who | mostly the raw speaker call found in the protocols |
| speaker | speaker_name | consolidated speaker names |
| parliamentary_group | speaker_parlgroup | consolidated parliamentary group affiliation of a speaker |
| party | speaker_party | consolidated party affiliation of a speaker |
| role | speaker_role | role of a speaker (e.g. member of parliament, governmental actor, etc.) |
| - | p | a paragraph node, technically parent of sentence nodes |
| interjection | p_type | the type of paragraph, used to indicate paragraphs which are not speech (such as interjections) |
| - | s | a sentence node |
| - | ne | a named entity node to represent (nested) named entities |
| - | ne_type | the type of named entity |
As described in the release note of the previous beta release, the labels of the attributes purposefully deviate from those of GermaParl v1 to better represent the hierarchical structure of the corpus. See also section “data formats” in this release note.
The CWB version of GermaParl2 includes linguistic annotation layers. Aside from tokenization and sentence segmentation as well as named entities which are encoded as structural attributes, the linguistic annotation comprises of Part-of-Speech annotation (providing POS-Tags in both the Stuttgart-Tübingen-Tagset and the UD-Tagset) and lemmatization. For tokenization, sentence segmentation, Part-of-Speech annotation with the UD tagset and Named Entity Recognition, Stanford CoreNLP is used. POS-Tags in the Stuttgart-Tübingen-Tagsets and Lemmata are added using the TreeTagger.
Available Data Formats
GermaParl2 is provided in two formats:
-
An XML format which is inspired by the TEI-Standard
-
A CWB corpus based on these TEI-XML files
The XML version of the corpus which is available on GitHub is designed to provide the data as a persistent, interoperable format. XML is not necessarily the first choice for fast analyses of corpus data. We provide it as an interoperable data format for users that may have their own pipelines for processing large-scale linguistic data. While the structural annotation of the data – i.e. the segmentation of the text into individual utterances, etc. – is provided in the XML version of the data, this version is not linguistically annotated.
The Corpus Workbench (CWB)]is an efficient corpus management tool for large text corpora. For the CWB version of the corpus, the XML files are imported into the Corpus Workbench. During this process, some additional steps to harmonize metadata on speaker level are performed to further increase the usability of the CWB corpus. A tarball with the CWB version of GermaParl2 is available from Zenodo and can be used either by the CWB command line interface, graphical user-interfaces such as CQPweb or from within R, using the polmineR R package. The remainder of this release note focusses on the usage of GermaParl2 with R using polmineR.
Getting Started
To use GermaParl2 with polmineR, the first step is to install the corpus. This should be as easy as…
install.packages(“cwbtools”)
cwbtools::corpus_install(doi = "10.5281/zenodo.7949074")This will download the corpus and store it in an appropriate directory on your system. Depending on whether a CWB corpus has been installed before on the system, a dialogue will guide you through the process. If the previous beta version of GermaParl2 is already installed, the installation routine will suggest replacing the beta version with the new release. The downloaded data file is quite large, so depending on the available internet connection, this might take a few minutes.
After installing all necessary packages and the corpus itself, the corpus should be available:
library(polmineR)
corpus() # should include GERMAPARL2
size(“GERMAPARL2”) # test the functionality To increase the accessibility of the resource, we would like to offer the possibility of a rather informal exchange in the form of virtual cooking sessions (via Zoom). At the beginning of each lesson, we – members of the PolMine team – present a small recipe or use case involving polmineR and GermaParl2. These use cases should provide users with useful code snippets and should serve as an ice breaker for the subsequent Q&A and discussion.
The first Cookin’ with GermaParl session will address typical first analytical scenarios with polmineR and GermaParl2 and will take place on
June 1, 2023, 13:00 – 14:00
If you want to participate in these Cookin’ with GermaParl sessions, please send an email to stine.ziegler@uni-due.de.
What is new?
GermaPar2 has benefitted substantially from the feedback we received from beta users. The final release version of GermaParl2 differs in three substantial aspects from the previous beta releases:
-
Increased data quality
-
Genuine preparation of the debates included in GermaParl v1
-
Changed enrichment of the speaker metadata
Increased Data Quality
After some additional steps of quality control and user feedback, further improvements in data quality were implemented. In particular, the detection of procedural comments. In the XML version, these are annotated as
Fresh preparation of legislative periods 13–18
The previous version of GermaParl (GermaParl v1) covered legislative periods 13 to 18. Until now, this data was incorporated into GermaParl2 by using the TEIs which have been prepared for GermaParl v1, making some minor adjustments such as fixing metadata and speaker attributes where necessary. This was done to ensure that the high data quality of GermaParl v1 is included in GermaParl2.
However, this approach has one drawback. Using the structurally annotated TEI documents limits the possibility for comprehensive changes to the structure. In particular, the identification of additional speakers which might have been missed in the previous version is difficult when reusing the previous TEIs. Furthermore, it adds a layer of complexity to the data preparation process, limiting reproducibility and clean documentation.
For the final version of GermaParl2, a new approach was used that should retain the quality of the existing data while allowing further improvements of the data. Instead of reusing the existing TEIs, the raw text was processed again from scratch making use of existing workflows instead of existing data. The result is very similar to GermaParl v1. However, additional speakers were identified – in particular speakers of the federal council but also some speakers such as the “Alterspräsident”. The inclusion of the 50th session of the 15th legislative period and the 135th session of the 18th legislative period which were missing previously are some major improvements aside from some minor changes to fill gaps in the document metadata, etc.
It can be noted that the new version of the period covered by GermaParl v1 does differ in some additional aspects such as the reconstruction of paragraphs. Slight differences are expected.
Enrichment of the speaker metadata
On speaker level, GermaParl2 like its predecessor, includes not only data which can be found in the protocols themselves – such as a speakers (family) name or the corresponding affiliation to a parliamentary group – but also additional information such as the party affiliation and a consolidated name of the speaker. In previous versions, the source of this additional information was mostly Wikipedia. For Members of Parliament this has changed. For the most part, data from the Stammdaten-File of the German Bundestag (available here)[https://www.bundestag.de/services/opendata] is used. It provides a host of additional information. However, since a speaker’s party affiliation are static in this Stammdaten file – each speaker has exactly one party assigned –, for GermaParl2 the Stammdaten are enriched with party assignments retrieved from Wikipedia. We mainly add the full name of the speaker and these party affiliations to the textual data. The switch should make the assignment of this additional information more transparent and reproducible and should result in more consistent annotations. It is planned to make the dataset available as an R package soon.
Regarding this enrichment of speaker data, there are some other improvements in how the parliamentary data and the external data is matched. In addition, some minor harmonization of attributes such as the names of parties and parliamentary groups was applied to increase the usability of the resource.
Next Steps
The public release of GermaParl2 is an important milestone in the evolution of the PolMine project. But there is more to come. As mentioned in the previous release note, a new XML version of the corpus is already under preparation. It moves the TEI-like XML we use now to a truly interoperable format based on the ParlaMint standard.
If you wish to stay informed about the latest developments regarding GermaParl, you can subscribe to our project newsletter by emailing stine.ziegler@uni-due.de.
Feedback welcome!
We are confident that the data quality of the current release version is high. However, we are certain that further improvements in data quality are still achievable as soon as more users put the data to active use. In this sense, GermaParl v2.1.0 is already on the horizon. With GermaParl v2.0.0 as a solid foundation, improving data quality further should become a community effort. The best way to contribute to this endeavor is by reporting bugs and flaws in the data as well as suggestions and feature requests for further releases. One way to get in touch in this regard is by creating so called issues on (GitHub)[https://docs.github.com/en/issues/tracking-your-work-with-issues/creating-an-issue] in the (GermaParl2 repository)[https://github.com/PolMine/GermaParl2]. As mentioned above, this repository contains the TEI version of the current GermaParl corpus and thus should work as the hub for collecting feedback for both the XML and the CWB version of the corpus as the latter is based on the former.
While GitHub issues allow users and developers of the resource to collaborate, discuss and evaluate different solutions interactively, reporting bugs and suggestions is of course also possible by email. If you prefer contributing by mail, please contact stine.ziegler@uni-due.de with any suggestions you might have.
Aside from suggesting improvements for the data itself, we released the preparation workflow of the data. In the corresponding repository, suggestions are welcome as well.
Acknowledgments
The data quality of GermaParl we are able to offer at this stage has benefitted significantly from a cooperation with the SOLDISK project at the University of Hildesheim, and comprehensive manual quality control of the data carried out by the SOLDISK team. A very special thanks goes to Hannes Schammann, Max Kisselew, Franziska Ziegler, Carina Böker, Jennifer Elsner and Carolin McCrea.
We also would like to thank all beta users for their invaluable feedback.
Funding statement
We gratefully acknowledge funding from the German National Research Data Infrastructure (Nationale Forschungsdateninfrastruktur / NFDI). Funding from KonsortSWD has advanced the data preparation tool set to facilitate the robust annotation of additional annotation layers in large corpora (such as Named Entities). This is instrumental for linking parliamentary data with other data. KonsortSWD is funded by the German Research Foundation (DFG) as part of the National Research Data Infrastructure Germany (Nationale Forschungsdateninfrastruktur, NFDI) under project number 442494171.
Funding from the Text+ consortium is instrumental for updates of the corpus, quality control and keeping data formats up with current and future developments. Text+ is funded by the German Research Foundation (DFG) as part of the NFDI under project number 460033370.
Subscribe via RSS